
Uncovering SEO Opportunities via Log Files
Posted by RobinRozhon
I use web crawlers on a daily basis. While they are very useful, they only imitate search engine crawlers’ behavior, which means you aren’t always getting the full picture.
The only tool that can give you a real overview of how search engines crawl your site are log files. Despite this, many people are still obsessed with crawl budget — the number of URLs Googlebot can and wants to crawl.
Log file analysis may discover URLs on your site that you had no idea about but that search engines are crawling anyway — a major waste of Google server resources (Google Webmaster Blog):
“Wasting server resources on pages like these will drain crawl activity from pages that do actually have value, which may cause a significant delay in discovering great content on a site.”
While it’s a fascinating topic, the fact is that most sites don’t need to worry that much about crawl budget —an observation shared by John Mueller (Webmaster Trends Analyst at Google) quite a few times already.
There’s still a huge value in analyzing logs produced from those crawls, though. It will show what pages Google is crawling and if anything needs to be fixed.
When you know exactly what your log files are telling you, you’ll gain valuable insights about how Google crawls and views your site, which means you can optimize for this data to increase traffic. And the bigger the site, the greater the impact fixing these issues will have.
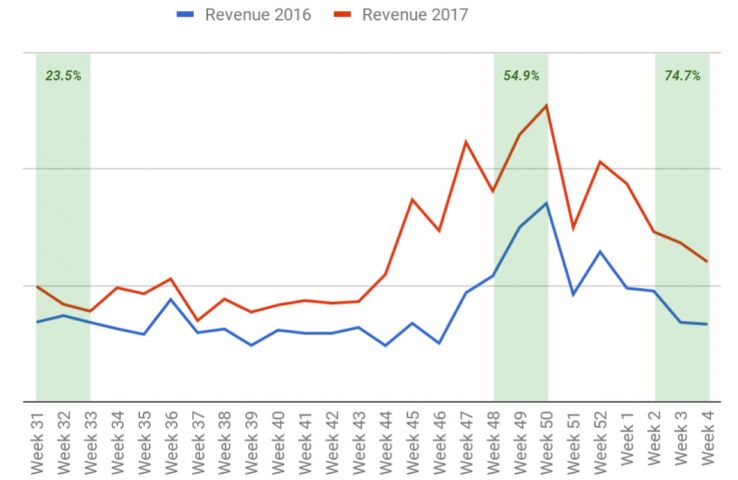
What are server logs?
A log file is a recording of everything that goes in and out of a server. Think of it as a ledger of requests made by crawlers and real users. You can see exactly what resources Google is crawling on your site.
You can also see what errors need your attention. For instance, one of the issues we uncovered with our analysis was that our CMS created two URLs for each page and Google discovered both. This led to duplicate content issues because two URLs with the same content was competing against each other.
Analyzing logs is not rocket science — the logic is the same as when working with tables in Excel or Google Sheets. The hardest part is getting access to them — exporting and filtering that data.
Looking at a log file for the first time may also feel somewhat daunting because when you open one, you see something like this:
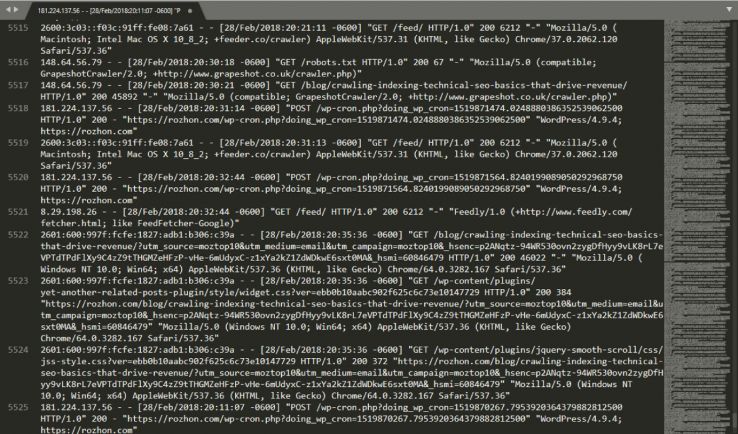
Calm down and take a closer look at a single line:
66.249.65.107 - - [08/Dec/2017:04:54:20 -0400] "GET /contact/ HTTP/1.1" 200 11179 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
You’ll quickly recognize that:
- 66.249.65.107 is the IP address (who)
- [08/Dec/2017:04:54:20 -0400] is the Timestamp (when)
- GET is the Method
- /contact/ is the Requested URL (what)
- 200 is the Status Code (result)
- 11179 is the Bytes Transferred (size)
- “-” is the Referrer URL (source) — it’s empty because this request was made by a crawler
- Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) is the User Agent (signature) — this is user agent of Googlebot (Desktop)
Once you know what each line is composed of, it’s not so scary. It’s just a lot of information. But that’s where the next step comes in handy.
Tools you can use
There are many tools you can choose from that will help you analyze your log files. I won’t give you a full run-down of available ones, but it’s important to know the difference between static and real-time tools.
- Static — This only analyzes a static file. You can’t extend the time frame. Want to analyze another period? You need to request a new log file. My favourite tool for analyzing static log files is Power BI.
- Real-time — Gives you direct access to logs. I really like open source ELK Stack (Elasticsearch, Logstash, and Kibana). It takes a moderate effort to implement it but once the stack is ready, it allows me changing the time frame based on my needs without needing to contact our developers.
Start analyzing
Don’t just dive into logs with a hope to find something — start asking questions. If you don’t formulate your questions at the beginning, you will end up in a rabbit hole with no direction and no real insights.
Here are a few samples of questions I use at the start of my analysis:
- Which search engines crawl my website?
- Which URLs are crawled most often?
- Which content types are crawled most often?
- Which status codes are returned?
If you see that Google is crawling non-existing pages (404), you can start asking which of those requested URLs return 404 status code.
Order the list by the number of requests, evaluate the ones with the highest number to find the pages with the highest priority (the more requests, the higher priority), and consider whether to redirect that URL or do any other action.

If you use a CDN or cache server, you need to get that data as well to get the full picture.
Segment your data
Grouping data into segments provides aggregate numbers that give you the big picture. This makes it easier to spot trends you might have missed by looking only at individual URLs. You can locate problematic sections and drill down if needed.
There are various ways to group URLs:
- Group by content type (single product pages vs. category pages)
- Group by language (English pages vs. French pages)
- Group by storefront (Canadian store vs. US store)
- Group by file format (JS vs. images vs. CSS)
Don’t forget to slice your data by user-agent. Looking at Google Desktop, Google Smartphone, and Bing all together won’t surface any useful insights.
Monitor behavior changes over time
Your site changes over time, which means so will crawlers’ behavior. Googlebot often decreases or increases the crawl rate based on factors such as a page’s speed, internal link structure, and the existence of crawl traps.
It’s a good idea to check in with your log files throughout the year or when executing website changes. I look at logs almost on a weekly basis when releasing significant changes for large websites.
By analyzing server logs twice a year, at the very least, you’ll surface changes in crawler’s behavior.
Watch for spoofing
Spambots and scrapers don’t like being blocked, so they may fake their identity — they leverage Googlebot’s user agent to avoid spam filters.
To verify if a web crawler accessing your server really is Googlebot, you can run a reverse DNS lookup and then a forward DNS lookup. More on this topic can be found in Google Webmaster Help Center.
Merge logs with other data sources
While it’s no necessary to connect to other data sources, doing so will unlock another level of insight and context that regular log analysis might not be able to give you. An ability to easily connect multiple datasets and extract insights from them is the main reason why Power BI is my tool of choice, but you can use any tool that you’re familiar with (e.g. Tableau).
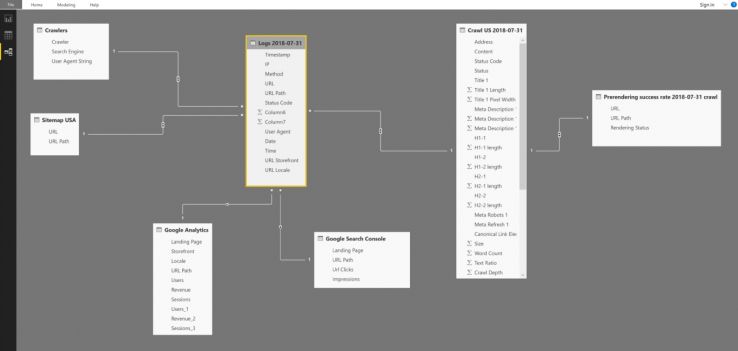
Blend server logs with multiple other sources such as Google Analytics data, keyword ranking, sitemaps, crawl data, and start asking questions like:
- What pages are not included in the sitemap.xml but are crawled extensively?
- What pages are included in the Sitemap.xml file but are not crawled?
- Are revenue-driving pages crawled often?
- Is the majority of crawled pages indexable?
You may be surprised by the insights you’ll uncover that can help strengthen your SEO strategy. For instance, discovering that almost 70 percent of Googlebot requests are for pages that are not indexable is an insight you can act on.
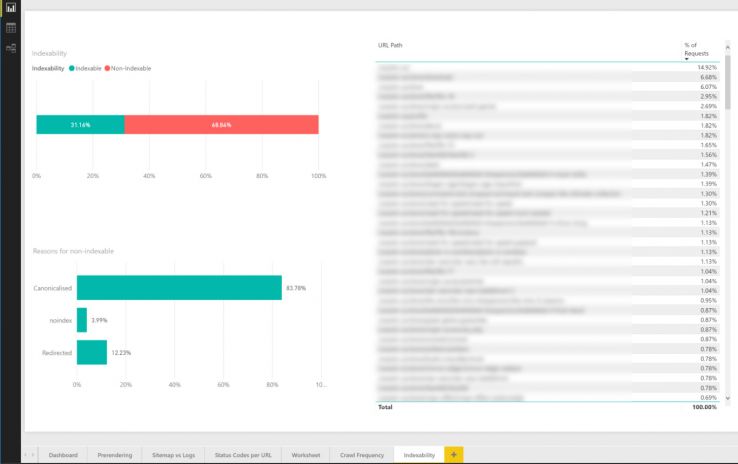
You can see more examples of blending log files with other data sources in my post about advanced log analysis.
Use logs to debug Google Analytics
Don’t think of server logs as just another SEO tool. Logs are also an invaluable source of information that can help pinpoint technical errors before they become a larger problem.
Last year, Google Analytics reported a drop in organic traffic for our branded search queries. But our keyword tracking tool, STAT Search Analytics, and other tools showed no movement that would have warranted the drop. So, what was going on?
Server logs helped us understand the situation: There was no real drop in traffic. It was our newly deployed WAF (Web Application Firewall) that was overriding the referrer, which caused some organic traffic to be incorrectly classified as direct traffic in Google Analytics.
Using log files in conjunction with keyword tracking in STAT helped us uncover the whole story and diagnose this issue quickly.
Putting it all together
Log analysis is a must-do, especially once you start working with large websites.
My advice is to start with segmenting data and monitoring changes over time. Once you feel ready, explore the possibilities of blending logs with your crawl data or Google Analytics. That’s where great insights are hidden.
Want more?
Ready to learn how to get cracking and tracking some more? Reach out and request a demo to get your very own tailored walkthrough of STAT.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
![]()







Recent Comments