
Rewriting the Beginner’s Guide to SEO, Chapter 5: Technical Optimization
Posted by BritneyMuller
After a short break, we’re back to share our working draft of Chapter 5 of the Beginner’s Guide to SEO with you! This one was a whopper, and we’re really looking forward to your input. Giving beginner SEOs a solid grasp of just what technical optimization for SEO is and why it matters — without overwhelming them or scaring them off the subject — is a tall order indeed. We’d love to hear what you think: did we miss anything you think is important for beginners to know? Leave us your feedback in the comments!
And in case you’re curious, check back on our outline, Chapter One, Chapter Two, Chapter Three, and Chapter Four to see what we’ve covered so far.
Chapter 5: Technical Optimization
Basic technical knowledge will help you optimize your site for search engines and establish credibility with developers.
Now that you’ve crafted valuable content on the foundation of solid keyword research, it’s important to make sure it’s not only readable by humans, but by search engines too!
You don’t need to have a deep technical understanding of these concepts, but it is important to grasp what these technical assets do so that you can speak intelligently about them with developers. Speaking your developers’ language is important because you will likely need them to carry out some of your optimizations. They’re unlikely to prioritize your asks if they can’t understand your request or see its importance. When you establish credibility and trust with your devs, you can begin to tear away the red tape that often blocks crucial work from getting done.
|
Pro tip: SEOs need cross-team support to be effective It’s vital to have a healthy relationship with your developers so that you can successfully tackle SEO challenges from both sides. Don’t wait until a technical issue causes negative SEO ramifications to involve a developer. Instead, join forces for the planning stage with the goal of avoiding the issues altogether. If you don’t, it can cost you in time and money later. |
Beyond cross-team support, understanding technical optimization for SEO is essential if you want to ensure that your web pages are structured for both humans and crawlers. To that end, we’ve divided this chapter into three sections:
- How websites work
- How search engines understand websites
- How users interact with websites
Since the technical structure of a site can have a massive impact on its performance, it’s crucial for everyone to understand these principles. It might also be a good idea to share this part of the guide with your programmers, content writers, and designers so that all parties involved in a site’s construction are on the same page.
1. How websites work
If search engine optimization is the process of optimizing a website for search, SEOs need at least a basic understanding of the thing they’re optimizing!
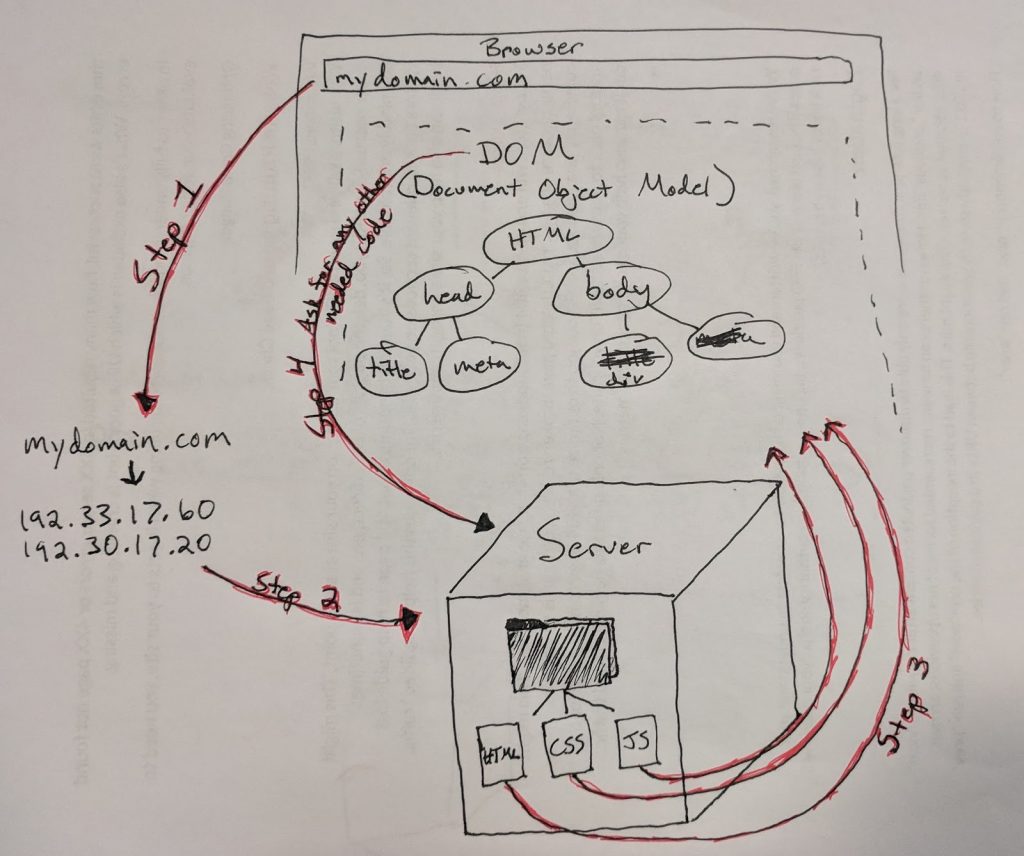
Below, we outline the website’s journey from domain name purchase all the way to its fully rendered state in a browser. An important component of the website’s journey is the critical rendering path, which is the process of a browser turning a website’s code into a viewable page.
Knowing this about websites is important for SEOs to understand for a few reasons:
- The steps in this webpage assembly process can affect page load times, and speed is not only important for keeping users on your site, but it’s also one of Google’s ranking factors.
- Google renders certain resources, like JavaScript, on a “second pass.” Google will look at the page without JavaScript first, then a few days to a few weeks later, it will render JavaScript, meaning SEO-critical elements that are added to the page using JavaScript might not get indexed.
Imagine that the website loading process is your commute to work. You get ready at home, gather your things to bring to the office, and then take the fastest route from your home to your work. It would be silly to put on just one of your shoes, take a longer route to work, drop your things off at the office, then immediately return home to get your other shoe, right? That’s sort of what inefficient websites do. This chapter will teach you how to diagnose where your website might be inefficient, what you can do to streamline, and the positive ramifications on your rankings and user experience that can result from that streamlining.
Before a website can be accessed, it needs to be set up!
- Domain name is purchased. Domain names like moz.com are purchased from a domain name registrar such as GoDaddy or HostGator. These registrars are just organizations that manage the reservations of domain names.
- Domain name is linked to IP address. The Internet doesn’t understand names like “moz.com” as website addresses without the help of domain name servers (DNS). The Internet uses a series of numbers called an Internet protocol (IP) address (ex: 127.0.0.1), but we want to use names like moz.com because they’re easier for humans to remember. We need to use a DNS to link those human-readable names with machine-readable numbers.
How a website gets from server to browser
- User requests domain. Now that the name is linked to an IP address via DNS, people can request a website by typing the domain name directly into their browser or by clicking on a link to the website.
- Browser makes requests. That request for a web page prompts the browser to make a DNS lookup request to convert the domain name to its IP address. The browser then makes a request to the server for the code your web page is constructed with, such as HTML, CSS, and JavaScript.
- Server sends resources. Once the server receives the request for the website, it sends the website files to be assembled in the searcher’s browser.
- Browser assembles the web page. The browser has now received the resources from the server, but it still needs to put it all together and render the web page so that the user can see it in their browser. As the browser parses and organizes all the web page’s resources, it’s creating a Document Object Model (DOM). The DOM is what you can see when you right click + “inspect element” on a web page in your Chrome browser (learn how to inspect elements in other browsers).
- Browser makes final requests. The browser will only show a web page after all the page’s necessary code is downloaded, parsed, and executed, so at this point, if the browser needs any additional code in order to show your website, it will make an additional request from your server.
- Website appears in browser. Whew! After all that, your website has now been transformed (rendered) from code to what you see in your browser.
|
Pro tip: Talk to your developers about async! Something you can bring up with your developers is shortening the critical rendering path by setting scripts to “async” when they’re not needed to render content above the fold, which can make your web pages load faster. Async tells the DOM that it can continue to be assembled while the browser is fetching the scripts needed to display your web page. If the DOM has to pause assembly every time the browser fetches a script (called “render-blocking scripts”), it can substantially slow down your page load. It would be like going out to eat with your friends and having to pause the conversation every time one of you went up to the counter to order, only resuming once they got back. With async, you and your friends can continue to chat even when one of you is ordering. You might also want to bring up other optimizations that devs can implement to shorten the critical rendering path, such as removing unnecessary scripts entirely, like old tracking scripts. |
Now that you know how a website appears in a browser, we’re going to focus on what a website is made of — in other words, the code (programming languages) used to construct those web pages.
The three most common are:
- HTML – What a website says (titles, body content, etc.)
- CSS – How a website looks (color, fonts, etc.)
- JavaScript – How it behaves (interactive, dynamic, etc.)
HTML: What a website says
HTML stands for hypertext markup language, and it serves as the backbone of a website. Elements like headings, paragraphs, lists, and content are all defined in the HTML.
Here’s an example of a webpage, and what its corresponding HTML looks like:

HTML is important for SEOs to know because it’s what lives “under the hood” of any page they create or work on. While your CMS likely doesn’t require you to write your pages in HTML (ex: selecting “hyperlink” will allow you to create a link without you having to type in “a href=”), it is what you’re modifying every time you do something to a web page such as adding content, changing the anchor text of internal links, and so on. Google crawls these HTML elements to determine how relevant your document is to a particular query. In other words, what’s in your HTML plays a huge role in how your web page ranks in Google organic search!
CSS: How a website looks
CSS stands for cascading style sheets, and this is what causes your web pages to take on certain fonts, colors, and layouts. HTML was created to describe content, rather than to style it, so when CSS entered the scene, it was a game-changer. With CSS, web pages could be “beautified” without requiring manual coding of styles into the HTML of every page — a cumbersome process, especially for large sites.
It wasn’t until 2014 that Google’s indexing system began to render web pages more like an actual browser, as opposed to a text-only browser. A black-hat SEO practice that tried to capitalize on Google’s older indexing system was hiding text and links via CSS for the purpose of manipulating search engine rankings. This “hidden text and links” practice is a violation of Google’s quality guidelines.
Components of CSS that SEOs, in particular, should care about:
- Since style directives can live in external stylesheet files (CSS files) instead of your page’s HTML, it makes your page less code-heavy, reducing file transfer size and making load times faster.
- Browsers still have to download resources like your CSS file, so compressing them can make your web pages load faster, and page speed is a ranking factor.
- Having your pages be more content-heavy than code-heavy can lead to better indexing of your site’s content.
- Using CSS to hide links and content can get your website manually penalized and removed from Google’s index.
JavaScript: How a website behaves
In the earlier days of the Internet, web pages were built with HTML. When CSS came along, webpage content had the ability to take on some style. When the programming language JavaScript entered the scene, websites could now not only have structure and style, but they could be dynamic.
JavaScript has opened up a lot of opportunities for non-static web page creation. When someone attempts to access a page that is enhanced with this programming language, that user’s browser will execute the JavaScript against the static HTML that the server returned, resulting in a web page that comes to life with some sort of interactivity.
You’ve definitely seen JavaScript in action — you just may not have known it! That’s because JavaScript can do almost anything to a page. It could create a pop up, for example, or it could request third-party resources like ads to display on your page.
JavaScript can pose some problems for SEO, though, since search engines don’t view JavaScript the same way human visitors do. That’s because of client-side versus server-side rendering. Most JavaScript is executed in a client’s browser. With server-side rendering, on the other hand, the files are executed at the server and the server sends them to the browser in their fully rendered state.
SEO-critical page elements such as text, links, and tags that are loaded on the client’s side with JavaScript, rather than represented in your HTML, are invisible from your page’s code until they are rendered. This means that search engine crawlers won’t see what’s in your JavaScript — at least not initially.
Google says that, as long as you’re not blocking Googlebot from crawling your JavaScript files, they’re generally able to render and understand your web pages just like a browser can, which means that Googlebot should see the same things as a user viewing a site in their browser. However, due to this “second wave of indexing” for client-side JavaScript, Google can miss certain elements that are only available once JavaScript is executed.
There are also some other things that could go wrong during Googlebot’s process of rendering your web pages, which can prevent Google from understanding what’s contained in your JavaScript:
- You’ve blocked Googlebot from JavaScript resources (ex: with robots.txt, like we learned about in Chapter 2)
- Your server can’t handle all the requests to crawl your content
- The JavaScript is too complex or outdated for Googlebot to understand
- JavaScript doesn’t “lazy load” content into the page until after the crawler has finished with the page and moved on.
Needless to say, while JavaScript does open a lot of possibilities for web page creation, it can also have some serious ramifications for your SEO if you’re not careful. Thankfully, there is a way to check whether Google sees the same thing as your visitors. To see a page how Googlebot views your page, use Google Search Console’s “Fetch and Render” tool. From your site’s Google Search Console dashboard, select “Crawl” from the left navigation, then “Fetch as Google.”
From this page, enter the URL you want to check (or leave blank if you want to check your homepage) and click the “Fetch and Render” button. You also have the option to test either the desktop or mobile version.
In return, you’ll get a side-by-side view of how Googlebot saw your page versus how a visitor to your website would have seen the page. Below, Google will also show you a list of any resources they may not have been able to get for the URL you entered.
Understanding the way websites work lays a great foundation for what we’ll talk about next, which is technical optimizations to help Google understand the pages on your website better.
2. How search engines understand websites
Search engines have gotten incredibly sophisticated, but they can’t (yet) find and interpret web pages quite like a human can. The following sections outline ways you can better deliver content to search engines.
Help search engines understand your content by structuring it with Schema
Imagine being a search engine crawler scanning down a 10,000-word article about how to bake a cake. How do you identify the author, recipe, ingredients, or steps required to bake a cake? This is where schema (Schema.org) markup comes in. It allows you to spoon-feed search engines more specific classifications for what type of information is on your page.
Schema is a way to label or organize your content so that search engines have a better understanding of what certain elements on your web pages are. This code provides structure to your data, which is why schema is often referred to as “structured data.” The process of structuring your data is often referred to as “markup” because you are marking up your content with organizational code.
JSON-LD is Google’s preferred schema markup (announced in May ‘16), which Bing also supports. To view a full list of the thousands of available schema markups, visit Schema.org or view the Google Developers Introduction to Structured Data for additional information on how to implement structured data. After you implement the structured data that best suits your web pages, you can test your markup with Google’s Structured Data Testing Tool.
In addition to helping bots like Google understand what a particular piece of content is about, schema markup can also enable special features to accompany your pages in the SERPs. These special features are referred to as “rich snippets,” and you’ve probably seen them in action. They’re things like:
- Top Stories carousel
- Review stars
- Sitelinks search boxes
- Recipes
Remember, using structured data can help enable a rich snippet to be present, but does not guarantee it. Other types of rich snippets will likely be added in the future as the use of schema markup increases.
Some last words of advice for schema success:
- You can use multiple types of schema markup on a page. However, if you mark up one element, like a product for example, and there are other products listed on the page, you must also mark up those products.
- Don’t mark up content that is not visible to visitors and follow Google’s Quality Guidelines. For example, if you add review structured markup to a page, make sure those reviews are actually visible on that page.
- If you have duplicate pages, Google asks that you mark up each duplicate page with your structured markup, not just the canonical version.
- Provide original and updated (if applicable) content on your structured data pages.
- Structured markup should be an accurate reflection of your page.
- Try to use the most specific type of schema markup for your content.
- Marked-up reviews should not be written by the business. They should be genuine unpaid business reviews from actual customers.
Tell search engines about your preferred pages with canonicalization
When Google crawls the same content on different web pages, it sometimes doesn’t know which page to index in search results. This is why the tag was invented: to help search engines better index the preferred version of content and not all its duplicates.
The rel=”canonical” tag allows you to tell search engines where the original, master version of a piece of content is located. You’re essentially saying, “Hey search engine! Don’t index this; index this source page instead.” So, if you want to republish a piece of content, whether exactly or slightly modified, but don’t want to risk creating duplicate content, the canonical tag is here to save the day.
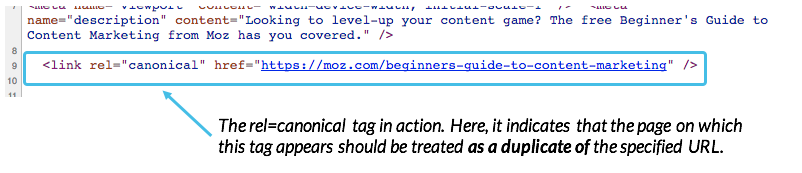
Proper canonicalization ensures that every unique piece of content on your website has only one URL. To prevent search engines from indexing multiple versions of a single page, Google recommends having a self-referencing canonical tag on every page on your site. Without a canonical tag telling Google which version of your web page is the preferred one, http://www.example.com could get indexed separately from http://example.com, creating duplicates.
“Avoid duplicate content” is an Internet truism, and for good reason! Google wants to reward sites with unique, valuable content — not content that’s taken from other sources and repeated across multiple pages. Because engines want to provide the best searcher experience, they will rarely show multiple versions of the same content, opting instead to show only the canonicalized version, or if a canonical tag does not exist, whichever version they deem most likely to be the original.
|
Pro tip: Distinguishing between content filtering & content penalties |
It’s also very common for websites to have multiple duplicate pages due to sort and filter options. For example, on an e-commerce site, you might have what’s called a faceted navigation that allows visitors to narrow down products to find exactly what they’re looking for, such as a “sort by” feature that reorders results on the product category page from lowest to highest price. This could create a URL that looks something like this: example.com/mens-shirts?sort=price_ascending. Add in more sort/filter options like color, size, material, brand, etc. and just think about all the variations of your main product category page this would create!
To learn more about different types of duplicate content, this post by Dr. Pete helps distill the different nuances.
3. How users interact with websites
In Chapter 1, we said that despite SEO standing for search engine optimization, SEO is as much about people as it is about search engines themselves. That’s because search engines exist to serve searchers. This goal helps explain why Google’s algorithm rewards websites that provide the best possible experiences for searchers, and why some websites, despite having qualities like robust backlink profiles, might not perform well in search.
When we understand what makes their web browsing experience optimal, we can create those experiences for maximum search performance.
Ensuring a positive experience for your mobile visitors
Being that well over half of all web traffic today comes from mobile, it’s safe to say that your website should be accessible and easy to navigate for mobile visitors. In April 2015, Google rolled out an update to its algorithm that would promote mobile-friendly pages over non-mobile-friendly pages. So how can you ensure that your website is mobile friendly? Although there are three main ways to configure your website for mobile, Google recommends responsive web design.
Responsive design
Responsive websites are designed to fit the screen of whatever type of device your visitors are using. You can use CSS to make the web page “respond” to the device size. This is ideal because it prevents visitors from having to double-tap or pinch-and-zoom in order to view the content on your pages. Not sure if your web pages are mobile friendly? You can use Google’s mobile-friendly test to check!
AMP
AMP stands for Accelerated Mobile Pages, and it is used to deliver content to mobile visitors at speeds much greater than with non-AMP delivery. AMP is able to deliver content so fast because it delivers content from its cache servers (not the original site) and uses a special AMP version of HTML and JavaScript. Learn more about AMP.
Mobile-first indexing
As of 2018, Google started switching websites over to mobile-first indexing. That change sparked some confusion between mobile-friendliness and mobile-first, so it’s helpful to disambiguate. With mobile-first indexing, Google crawls and indexes the mobile version of your web pages. Making your website compatible to mobile screens is good for users and your performance in search, but mobile-first indexing happens independently of mobile-friendliness.
This has raised some concerns for websites that lack parity between mobile and desktop versions, such as showing different content, navigation, links, etc. on their mobile view. A mobile site with different links, for example, will alter the way in which Googlebot (mobile) crawls your site and sends link equity to your other pages.
Breaking up long content for easier digestion
When sites have very long pages, they have the option of breaking them up into multiple parts of a whole. This is called pagination and it’s similar to pages in a book. In order to avoid giving the visitor too much all at once, you can break up your single page into multiple parts. This can be great for visitors, especially on e-commerce sites where there are a lot of product results in a category, but there are some steps you should take to help Google understand the relationship between your paginated pages. It’s called rel=”next” and rel=”prev.”
You can read more about pagination in Google’s official documentation, but the main takeaways are that:
- The first page in a sequence should only have rel=”next” markup
- The last page in a sequence should only have rel=”prev” markup
- Pages that have both a preceding and following page should have both rel=”next” and rel=”prev”
- Since each page in the sequence is unique, don’t canonicalize them to the first page in the sequence. Only use a canonical tag to point to a “view all” version of your content, if you have one.
- When Google sees a paginated sequence, it will typically consolidate the pages’ linking properties and send searchers to the first page
|
Pro tip: rel=”next/prev” should still have anchor text and live within an link |
Improving page speed to mitigate visitor frustration
Google wants to serve content that loads lightning-fast for searchers. We’ve come to expect fast-loading results, and when we don’t get them, we’ll quickly bounce back to the SERP in search of a better, faster page. This is why page speed is a crucial aspect of on-site SEO. We can improve the speed of our web pages by taking advantage of tools like the ones we’ve mentioned below. Click on the links to learn more about each.
- Google’s PageSpeed Insights tool & best practices documentation
- GTMetrix
- Google’s Mobile Website Speed & Performance Tester
- Google Lighthouse
Images are one of the main culprits of slow pages!
As discussed in Chapter 4, images are one of the number-one reasons for slow-loading web pages! In addition to image compression, optimizing image alt text, choosing the right image format, and submitting image sitemaps, there are other technical ways to optimize the speed and way in which images are shown to your users. Some primary ways to improve image delivery are as follows:
SRCSET: How to deliver the best image size for each device
The SRCSET attribute allows you to have multiple versions of your image and then specify which version should be used in different situations. This piece of code is added to the tag (where your image is located in the HTML) to provide unique images for specific-sized devices.
This is like the concept of responsive design that we discussed earlier, except for images!
This doesn’t just speed up your image load time, it’s also a unique way to enhance your on-page user experience by providing different and optimal images to different device types.
|
Pro tip: There are more than just three image size versions! |
Show visitors image loading is in progress with lazy loading
Lazy loading occurs when you go to a webpage and, instead of seeing a blank white space for where an image will be, a blurry lightweight version of the image or a colored box in its place appears while the surrounding text loads. After a few seconds, the image clearly loads in full resolution. The popular blogging platform Medium does this really well.
The low resolution version is initially loaded, and then the full high resolution version. This also helps to optimize your critical rendering path! So while all of your other page resources are being downloaded, you’re showing a low-resolution teaser image that helps tell users that things are happening/being loaded. For more information on how you should lazy load your images, check out Google’s Lazy Loading Guidance.
Improve speed by condensing and bundling your files
Page speed audits will often make recommendations such as “minify resource,” but what does that actually mean? Minification condenses a code file by removing things like line breaks and spaces, as well as abbreviating code variable names wherever possible.
“Bundling” is another common term you’ll hear in reference to improving page speed. The process of bundling combines a bunch of the same coding language files into one single file. For example, a bunch of JavaScript files could be put into one larger file to reduce the amount of JavaScript files for a browser.
By both minifying and bundling the files needed to construct your web page, you’ll speed up your website and reduce the number of your HTTP (file) requests.
Improving the experience for international audiences
Websites that target audiences from multiple countries should familiarize themselves with international SEO best practices in order to serve up the most relevant experiences. Without these optimizations, international visitors might have difficulty finding the version of your site that caters to them.
There are two main ways a website can be internationalized:
- Language
Sites that target speakers of multiple languages are considered multilingual websites. These sites should add something called an hreflang tag to show Google that your page has copy for another language. Learn more about hreflang. - Country
Sites that target audiences in multiple countries are called multi-regional websites and they should choose a URL structure that makes it easy to target their domain or pages to specific countries. This can include the use of a country code top level domain (ccTLD) such as “.ca” for Canada, or a generic top-level domain (gTLD) with a country-specific subfolder such as “example.com/ca” for Canada. Learn more about locale-specific URLs.
You’ve researched, you’ve written, and you’ve optimized your website for search engines and user experience. The next piece of the SEO puzzle is a big one: establishing authority so that your pages will rank highly in search results.
![]()







Recent Comments