
Information gain in SEO: What it is and why it matters
A Google patent on “information gain score” was granted in June 2022. I believe it’s no coincidence that several algorithm updates – including the helpful content update – followed.
Is information gain score a key way for Google to prioritize valuable content that is “original, high-quality, people-first content demonstrating qualities E-E-A-T”?
My hypothesis: yes. Here’s why.
What is an information gain score?
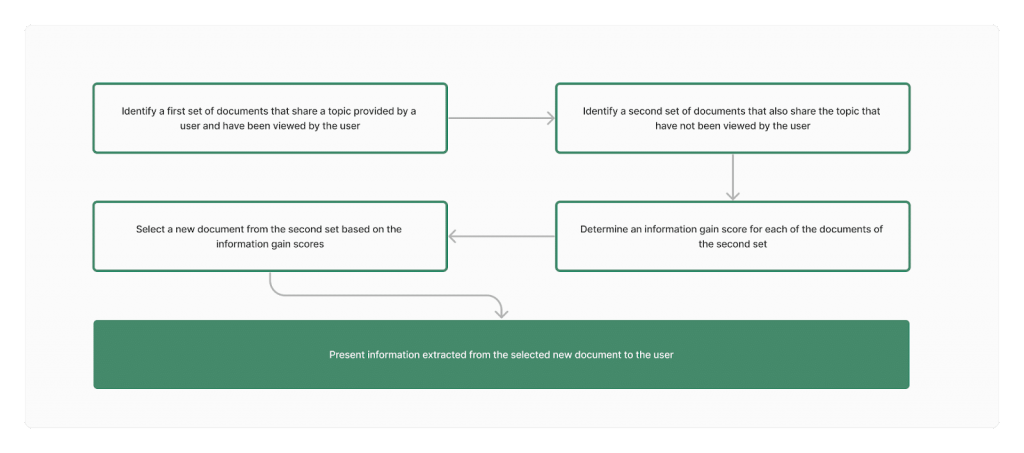
An information gain score is essentially a measure of how unique your content is from the rest of the corpus. Here, the corpus would be all the potential documents that Google analyses in ranking for the particular query searched.
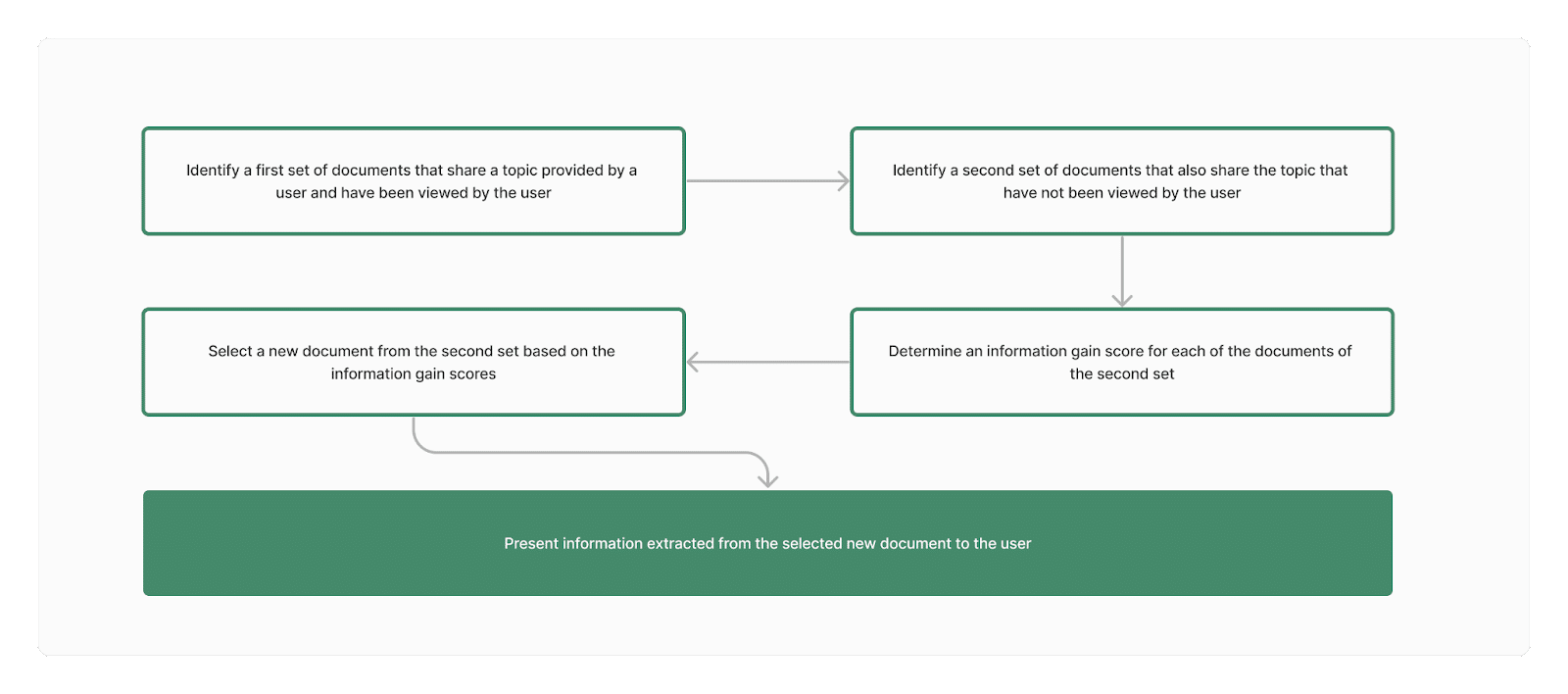
In the patent, most of the scenarios given to calculate information gain scores are done after subsequent queries or document views and search result views. It’s a learning process specific to the individual and/or to the topic they’re searching about.
The late Bill Slawski wrote a technical breakdown of this process when the patent was still in review in 2020.
One of the interesting things I see in the patent language is this:
Google is giving leeway for information gain scores to be calculated algorithmically and applied as training data across machine learning models.
The need for a first set of documents to calculate the information gain score may become obsolete in the future:
“[i]n some implementations, data from each of the documents of the second set of documents may be applied across a machine learning model as input.”
How does information gain affect search rankings?
From a real-world perspective, this means Google:
- Has a way of calculating how unique your content is from the rest of the content in that topic area.
- Has a metric to actively promote or demote content based on that level of difference or sameness.
The information gain score suggests a new algorithm element targeting AI-generated content and new content farms.
Consequently, content might be demoted if it lacks uniqueness, even if it consists of different words arranged differently.
Skyscraper content could be a part of this targeted demotion.
The information gain score and helpful content system are forcing innovation where there’s currently a sea of “perfectly optimized” content.
Get the daily newsletter search marketers rely on.
See terms.
Can information gain improve your website visibility?
Using information gain to create or update content is a two-fold process.
- Analyze the source of your data.
- Identify market opportunities.
In an ideal scenario, it would be fascinating to see what an expert or sales manager could produce if asked to write about solving a client’s X problem without any “SEO requirements” or using Google. The result might be a surprisingly innovative and appropriate response.
Most of us don’t have the luxury of a shot in the dark like that and need a bit more structure to change, update and adapt how we create content.
So let’s break down how we can shift that approach.
Where are you getting your information from?
While it may feel like a step back, prepare to spend more time researching for content than you perhaps ever have.
If you’re getting your information solely from the web and the SERP you want to rank for, you may be a part of the problem. We all do it, but it’s kinda lazy, right?
Great, quality content takes time.
The content we publish that we’re amplifying and using as a way to promote our companies, our brands, and ourselves should be able to meet the “thought leadership” mark.
What does that take? The basis of thought leadership is essentially informed opinion.
This requires you to take a stance, have a specific opinion, or come to a particular conclusion.
And to do that, you need the information to substantiate that opinion, or you should.
At any company, you will have unique data that’s just waiting for you to use in an article or tool for your clients and customers, like:
- Feedback and logs from your customer service team.
- Your reviews.
- Feedback and sales calls from your sales team.
- Your product usage data, if it can be aggregated and published.
These are all content sources that a competitor can’t easily duplicate.
They can also be turned into rich media experiences that Google can’t create.
It’s also informed by your actual customers and their actual experiences.
A lot of the content the search results may be “telling” you to create may not actually be appropriate for your customers.
Starting with your own data will naturally filter out a lot of content that’s written purely for search engines.
What opportunities are there in the market?
While it’s tempting to go to Google or Bing and follow the format of the top-ranking article in search results, remember that Google only ranks it the highest because it’s the best of what they have access to.
They can’t create their own content (yet) to answer exactly what a person is searching for if it doesn’t already exist.
So the content ranking could be absolute garbage for meeting actual expertise and providing a solid answer, but because it’s the best of the worst, it’s what ranks.
So when creating new content, we should also look at topical relevance and areas related to the topic you’re writing about that perhaps other competitors aren’t taking advantage of.
Tools that can help you see the existing topical relationships of your competitors include:
- Natural Language API demo
- Diffbot demo
- Orbitwise
Tools you can use to help understand the semantic topic relationships of your primary topic (that may not be covered by your competitors) include:
- MarketMuse
- TF-IDF via Ryte
- Keyword clustering with Semrush (paid)
- Create your own topic modeling tool using Latent Dirichlet Allocation and Python (not tested)
Each of these tools has its own trade-offs and considerations, and each should be weighed up with the data compromises your organization is making.
Like everything else, they’re also an approximation of how Google’s search engine ranking system works.
It’s also good to remember that the outpouring of recently published content from AI has real-world cost implications for Google.
More content means incrementally more expensive electricity bills, so they have a vested interest in cutting out as much content as possible before it goes through all three crawlers.
So find ways to create content that makes the cut for both your customers and Google.
The post Information gain in SEO: What it is and why it matters appeared first on Search Engine Land.







Recent Comments