
How Much Data Is Missing from Analytics? And Other Analytics Black Holes
Posted by Tom.Capper
If you’ve ever compared two analytics implementations on the same site, or compared your analytics with what your business is reporting in sales, you’ve probably noticed that things don’t always match up. In this post, I’ll explain why data is missing from your web analytics platforms and how large the impact could be. Some of the issues I cover are actually quite easily addressed, and have a decent impact on traffic — there’s never been an easier way to hit your quarterly targets. 😉
I’m going to focus on GA (Google Analytics), as it’s the most commonly used provider, but most on-page analytics platforms have the same issues. Platforms that rely on server logs do avoid some issues but are fairly rare, so I won’t cover them in any depth.
Side note: Our test setup (multiple trackers & customized GA)
On Distilled.net, we have a standard Google Analytics property running from an HTML tag in GTM (Google Tag Manager). In addition, for the last two years, I’ve been running three extra concurrent Google Analytics implementations, designed to measure discrepancies between different configurations.
(If you’re just interested in my findings, you can skip this section, but if you want to hear more about the methodology, continue reading. Similarly, don’t worry if you don’t understand some of the detail here — the results are easier to follow.)
Two of these extra implementations — one in Google Tag Manager and one on page — run locally hosted, renamed copies of the Google Analytics JavaScript file (e.g. www.distilled.net/static/js/au3.js, instead of www.google-analytics.com/analytics.js) to make them harder to spot for ad blockers. I also used renamed JavaScript functions (“tcap” and “Buffoon,” rather than the standard “ga”) and renamed trackers (“FredTheUnblockable” and “AlbertTheImmutable”) to avoid having duplicate trackers (which can often cause issues).
This was originally inspired by 2016-era best practice on how to get your Google Analytics setup past ad blockers. I can’t find the original article now, but you can see a very similar one from 2017 here.
Lastly, we have (“DianaTheIndefatigable”), which just has a renamed tracker, but uses the standard code otherwise and is implemented on-page. This is to complete the set of all combinations of modified and unmodified GTM and on-page trackers.

Two of Distilled’s modified on-page trackers, as seen on https://www.distilled.net/
Overall, this table summarizes our setups:
|
Tracker |
Renamed function? |
GTM or on-page? |
Locally hosted JavaScript file? |
|---|---|---|---|
|
Default |
No |
GTM HTML tag |
No |
|
FredTheUnblockable |
Yes – “tcap” |
GTM HTML tag |
Yes |
|
AlbertTheImmutable |
Yes – “buffoon” |
On page |
Yes |
|
DianaTheIndefatigable |
No |
On page |
No |
I tested their functionality in various browser/ad-block environments by watching for the pageviews appearing in browser developer tools:
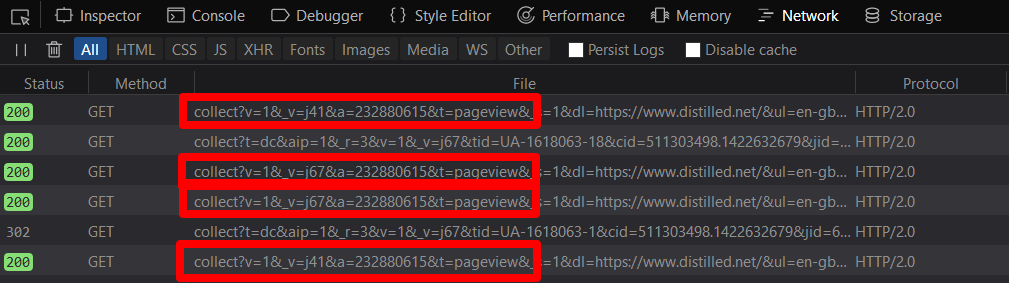
Reason 1: Ad Blockers
Ad blockers, primarily as browser extensions, have been growing in popularity for some time now. Primarily this has been to do with users looking for better performance and UX on ad-laden sites, but in recent years an increased emphasis on privacy has also crept in, hence the possibility of analytics blocking.
Effect of ad blockers
Some ad blockers block web analytics platforms by default, others can be configured to do so. I tested Distilled’s site with Adblock Plus and uBlock Origin, two of the most popular ad-blocking desktop browser addons, but it’s worth noting that ad blockers are increasingly prevalent on smartphones, too.
Here’s how Distilled’s setups fared:
(All numbers shown are from April 2018)
|
Setup |
Vs. Adblock |
Vs. Adblock with “EasyPrivacy” enabled |
Vs. uBlock Origin |
|---|---|---|---|
|
GTM |
Pass |
Fail |
Fail |
|
On page |
Pass |
Fail |
Fail |
|
GTM + renamed script & function |
Pass |
Fail |
Fail |
|
On page + renamed script & function |
Pass |
Fail |
Fail |
Seems like those tweaked setups didn’t do much!
Lost data due to ad blockers: ~10%
Ad blocker usage can be in the 15–25% range depending on region, but many of these installs will be default setups of AdBlock Plus, which as we’ve seen above, does not block tracking. Estimates of AdBlock Plus’s market share among ad blockers vary from 50–70%, with more recent reports tending more towards the former. So, if we assume that at most 50% of installed ad blockers block analytics, that leaves your exposure at around 10%.
Reason 2: Browser “do not track”
This is another privacy motivated feature, this time of browsers themselves. You can enable it in the settings of most current browsers. It’s not compulsory for sites or platforms to obey the “do not track” request, but Firefox offers a stronger feature under the same set of options, which I decided to test as well.
Effect of “do not track”
Most browsers now offer the option to send a “Do not track” message. I tested the latest releases of Firefox & Chrome for Windows 10.
|
Setup |
Chrome “do not track” |
Firefox “do not track” |
Firefox “tracking protection” |
|---|---|---|---|
|
GTM |
Pass |
Pass |
Fail |
|
On page |
Pass |
Pass |
Fail |
|
GTM + renamed script & function |
Pass |
Pass |
Fail |
|
On page + renamed script & function |
Pass |
Pass |
Fail |
Again, it doesn’t seem that the tweaked setups are doing much work for us here.
Lost data due to “do not track”: <1%
Only Firefox Quantum’s “Tracking Protection,” introduced in February, had any effect on our trackers. Firefox has a 5% market share, but Tracking Protection is not enabled by default. The launch of this feature had no effect on the trend for Firefox traffic on Distilled.net.
Reason 3: Filters
It’s a bit of an obvious one, but filters you’ve set up in your analytics might intentionally or unintentionally reduce your reported traffic levels.
For example, a filter excluding certain niche screen resolutions that you believe to be mostly bots, or internal traffic, will obviously cause your setup to underreport slightly.
Lost data due to filters: ???
Impact is hard to estimate, as setup will obviously vary on a site-by site-basis. I do recommend having a duplicate, unfiltered “master” view in case you realize too late you’ve lost something you didn’t intend to.
Reason 4: GTM vs. on-page vs. misplaced on-page
Google Tag Manager has become an increasingly popular way of implementing analytics in recent years, due to its increased flexibility and the ease of making changes. However, I’ve long noticed that it can tend to underreport vs. on-page setups.
I was also curious about what would happen if you didn’t follow Google’s guidelines in setting up on-page code.
By combining my numbers with numbers from my colleague Dom Woodman’s site (you’re welcome for the link, Dom), which happens to use a Drupal analytics add-on as well as GTM, I was able to see the difference between Google Tag Manager and misplaced on-page code (right at the bottom of the
tag) I then weighted this against my own Google Tag Manager data to get an overall picture of all 5 setups.Effect of GTM and misplaced on-page code
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
|
Google Tag Manager |
Modified & Google Tag Manager |
On-Page Code In |
Modified & On-Page Code In |
On-Page Code Misplaced In |
|
|---|---|---|---|---|---|
|
Chrome |
100.00% |
98.75% |
100.77% |
99.80% |
94.75% |
|
Safari |
100.00% |
99.42% |
100.55% |
102.08% |
82.69% |
|
Firefox |
100.00% |
99.71% |
101.16% |
101.45% |
90.68% |
|
Internet Explorer |
100.00% |
80.06% |
112.31% |
113.37% |
77.18% |
There are a few main takeaways here:
- On-page code generally reports more traffic than GTM
- Modified code is generally within a margin of error, apart from modified GTM code on Internet Explorer (see note below)
- Misplaced analytics code will cost you up to a third of your traffic vs. properly implemented on-page code, depending on browser (!)
- The customized setups, which are designed to get more traffic by evading ad blockers, are doing nothing of the sort.
It’s worth noting also that the customized implementations actually got less traffic than the standard ones. For the on-page code, this is within the margin of error, but for Google Tag Manager, there’s another reason — because I used unfiltered profiles for the comparison, there’s a lot of bot spam in the main profile, which primarily masquerades as Internet Explorer. Our main profile is by far the most spammed, and also acting as the baseline here, so the difference between on-page code and Google Tag Manager is probably somewhat larger than what I’m reporting.
I also split the data by mobile, out of curiosity:
Traffic as a percentage of baseline (standard Google Tag Manager implementation):
|
Google Tag Manager |
Modified & Google Tag Manager |
On-Page Code In |
Modified & On-Page Code In |
On-Page Code Misplaced In |
|
|---|---|---|---|---|---|
|
Desktop |
100.00% |
98.31% |
100.97% |
100.89% |
93.47% |
|
Mobile |
100.00% |
97.00% |
103.78% |
100.42% |
89.87% |
|
Tablet |
100.00% |
97.68% |
104.20% |
102.43% |
88.13% |
The further takeaway here seems to be that mobile browsers, like Internet Explorer, can struggle with Google Tag Manager.
Lost data due to GTM: 1–5%
Google Tag Manager seems to cost you a varying amount depending on what make-up of browsers and devices use your site. On Distilled.net, the difference is around 1.7%; however, we have an unusually desktop-heavy and tech-savvy audience (not much Internet Explorer!). Depending on vertical, this could easily swell to the 5% range.
Lost data due to misplaced on-page code: ~10%
On Teflsearch.com, the impact of misplaced on-page code was around 7.5%, vs Google Tag Manager. Keeping in mind that Google Tag Manager itself underreports, the total loss could easily be in the 10% range.
Bonus round: Missing data from channels
I’ve focused above on areas where you might be missing data altogether. However, there are also lots of ways in which data can be misrepresented, or detail can be missing. I’ll cover these more briefly, but the main issues are dark traffic and attribution.
Dark traffic
Dark traffic is direct traffic that didn’t really come via direct — which is generally becoming more and more common. Typical causes are:
- Untagged campaigns in email
- Untagged campaigns in apps (especially Facebook, Twitter, etc.)
- Misrepresented organic
- Data sent from botched tracking implementations (which can also appear as self-referrals)
It’s also worth noting the trend towards genuinely direct traffic that would historically have been organic. For example, due to increasingly sophisticated browser autocompletes, cross-device history, and so on, people end up “typing” a URL that they’d have searched for historically.
Attribution
I’ve written about this in more detail here, but in general, a session in Google Analytics (and any other platform) is a fairly arbitrary construct — you might think it’s obvious how a group of hits should be grouped into one or more sessions, but in fact, the process relies on a number of fairly questionable assumptions. In particular, it’s worth noting that Google Analytics generally attributes direct traffic (including dark traffic) to the previous non-direct source, if one exists.
Discussion
I was quite surprised by some of my own findings when researching this post, but I’m sure I didn’t get everything. Can you think of any other ways in which data can end up missing from analytics?
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
![]()







Recent Comments