
Regex for SEO: The simple language that powers AI and data analysis

Regex is a powerful – yet overlooked – tool in search and data analysis.
With just a single line, you can automate what would otherwise take dozens of lines of code.
Short for “regular expression,” regex is a sequence of characters used to define a pattern for matching text.
It’s what allows you to find, extract, or replace specific strings of data with precision.
In SEO, regex helps you extract and filter information efficiently – from analyzing keyword variations to cleaning messy query data.
But its value extends well beyond SEO.
Regex is also fundamental to natural language processing (NLP), offering insight into how machines read, parse, and process text – even how large language models (LLMs) tokenize language behind the scenes.
Regex uses in SEO and AI search
Before getting started with regex basics, I want to highlight some of its uses in our daily workflows.
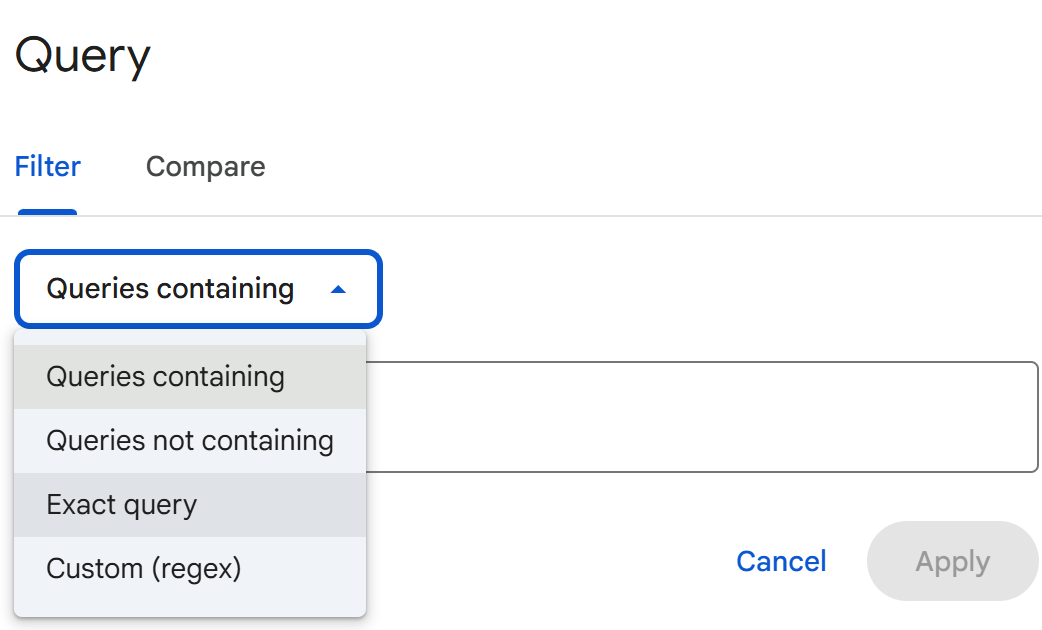
Google Search Console has a regex filter functionality to isolate specific query types.
One of the simplest regex expressions commonly used is the brand regex brandname1|brandname2|brandname3, which is very useful when users write your brand name in different ways.
Google Analytics also supports regex for defining filters, key events, segments, audiences, and content groups.
Looker Studio allows you to use regex to create filters, calculated fields, and validation rules.
Screaming Frog supports the use of regex to filter and extract data during a crawl and also to exclude specific URLs from your crawl.
Google Sheets enables you to test whether a cell matches a specific regex. Simply use the function REGEXMATCH (text, regular_expression).
In SEO, we’re surrounded by tools and features just waiting for a well-written regex to unlock their full potential.
Regex in NLP
If you’re building SEO tools, especially those that involve content processing, regex is your secret weapon.
It gives you the power to search, validate, and replace text based on advanced, customizable patterns.
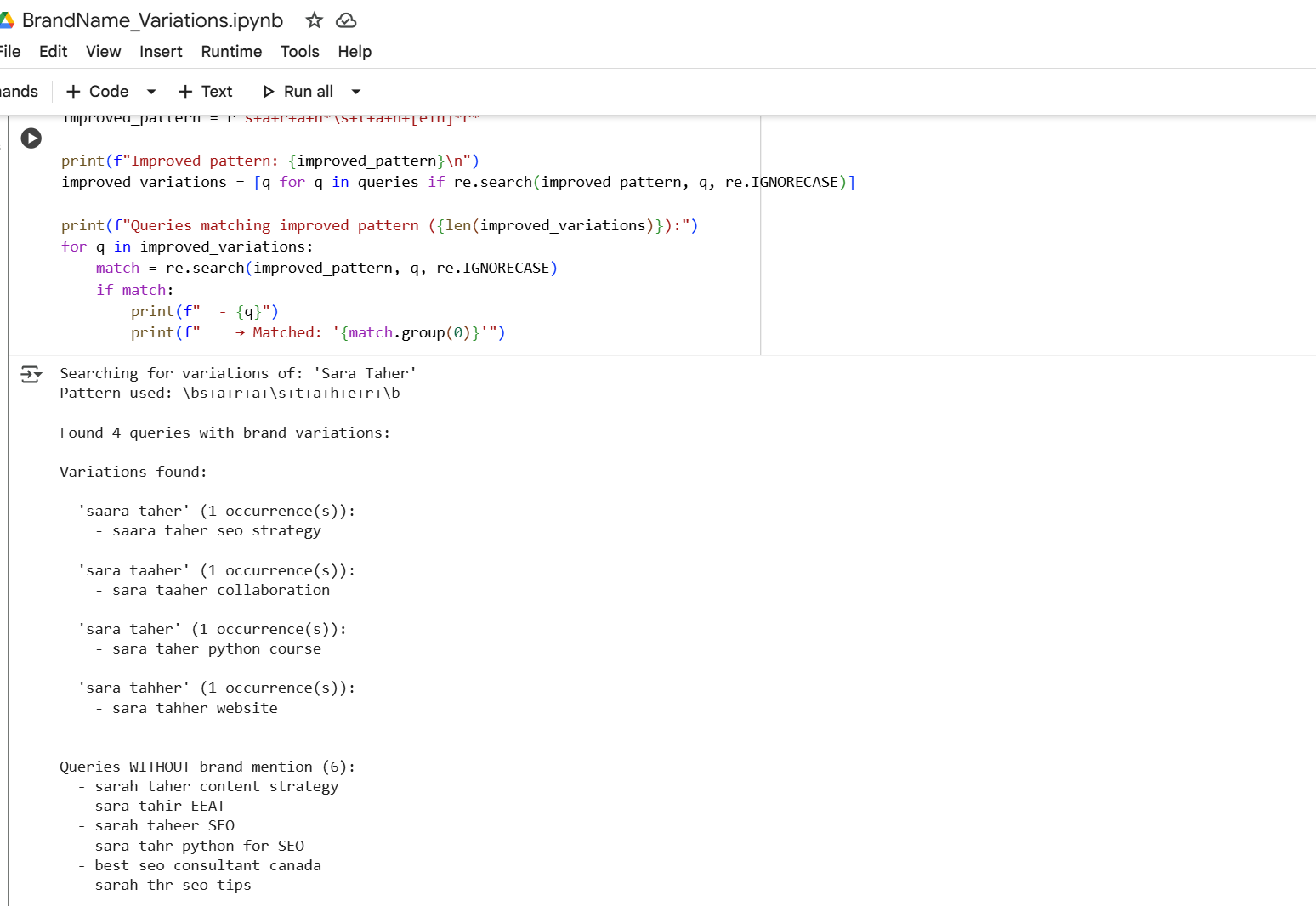
Here’s a Google Colab notebook with an example of a Python script that takes a list of queries and extracts different variations of my brand name.
You can easily customize this code by plugging it into ChatGPT or Claude alongside your brand name.
Get the newsletter search marketers rely on.
See terms.
How to write regex
I’m a fan of vibe coding – but not the kind where you skip the basics and rely entirely on LLMs.
After all, you can’t use a calculator properly if you don’t understand numbers or how addition, multiplication, division, and subtraction work.
I support the kind of vibe coding that builds on a little coding knowledge – enough to use LLMs effectively, test what they produce, and troubleshoot when needed.
Likewise, learning the basics of regex helps you use LLMs to create more advanced expressions.
Simple regex cheat sheet
| Symbol | Meaning |
. |
Matches any single character. |
^ |
Matches the start of a string. |
$ |
Matches the end of a string. |
* |
Matches 0 or more of the preceding character. |
+ |
Matches 1 or more of the preceding character. |
? |
Makes the preceding character optional (0 or 1 time). |
{} |
Matches the preceding character a specific number of times. |
[] |
Matches any one character inside the brackets. |
|
Escapes special characters or signals special sequences like d. |
` |
Matches a literal backtick character. |
() |
Groups characters together (for operators or capturing). |
Example usage
Here’s a list of 10 long-tail keywords. Let’s explore how different regex patterns filter them using the Regex101 tool.
- “Best vegan recipes for beginners.”
- “Affordable solar panels for home.”
- “How to train for a marathon.”
- “Electric cars with longest battery range.”
- “Meditation apps for stress relief.”
- “Sustainable fashion brands for women.”
- “DIY home workout routines without equipment.”
- “Travel insurance for adventure trips.”
- “AI writing software for SEO content.”
- “Coffee brewing techniques for espresso lovers.”
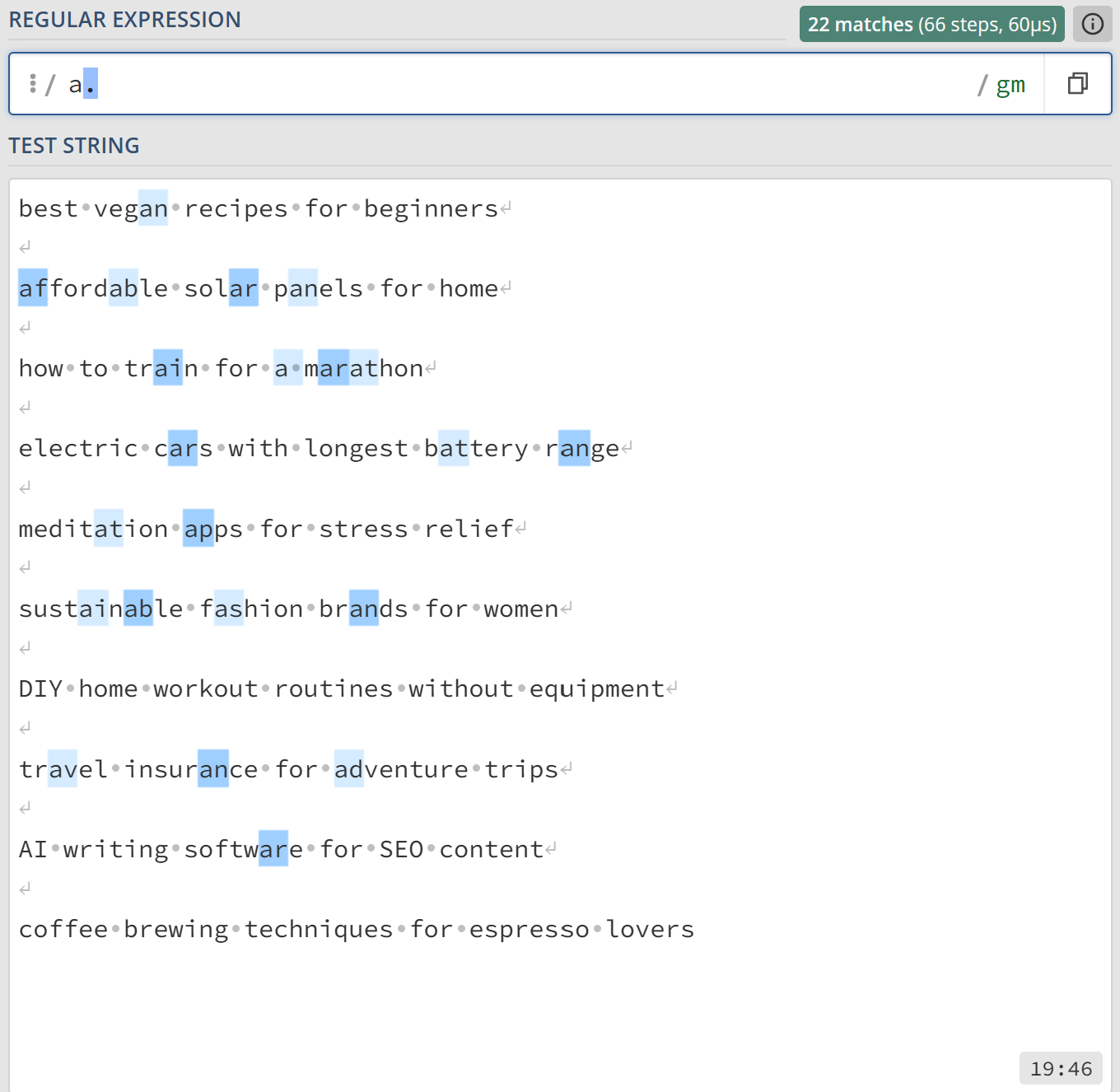
Example 1: Extract any two-character sequence that starts with an “a.” The second character can be anything (i.e., a, then anything).
- Regex:
a. - Output: (All highlighted words in the screenshot below.)
Example 2: Extract any string that starts with the letter “a” (i.e., a is the start of the string, then followed by anything).
- Regex:
^a. - Output: (All highlighted words in screenshot below.)
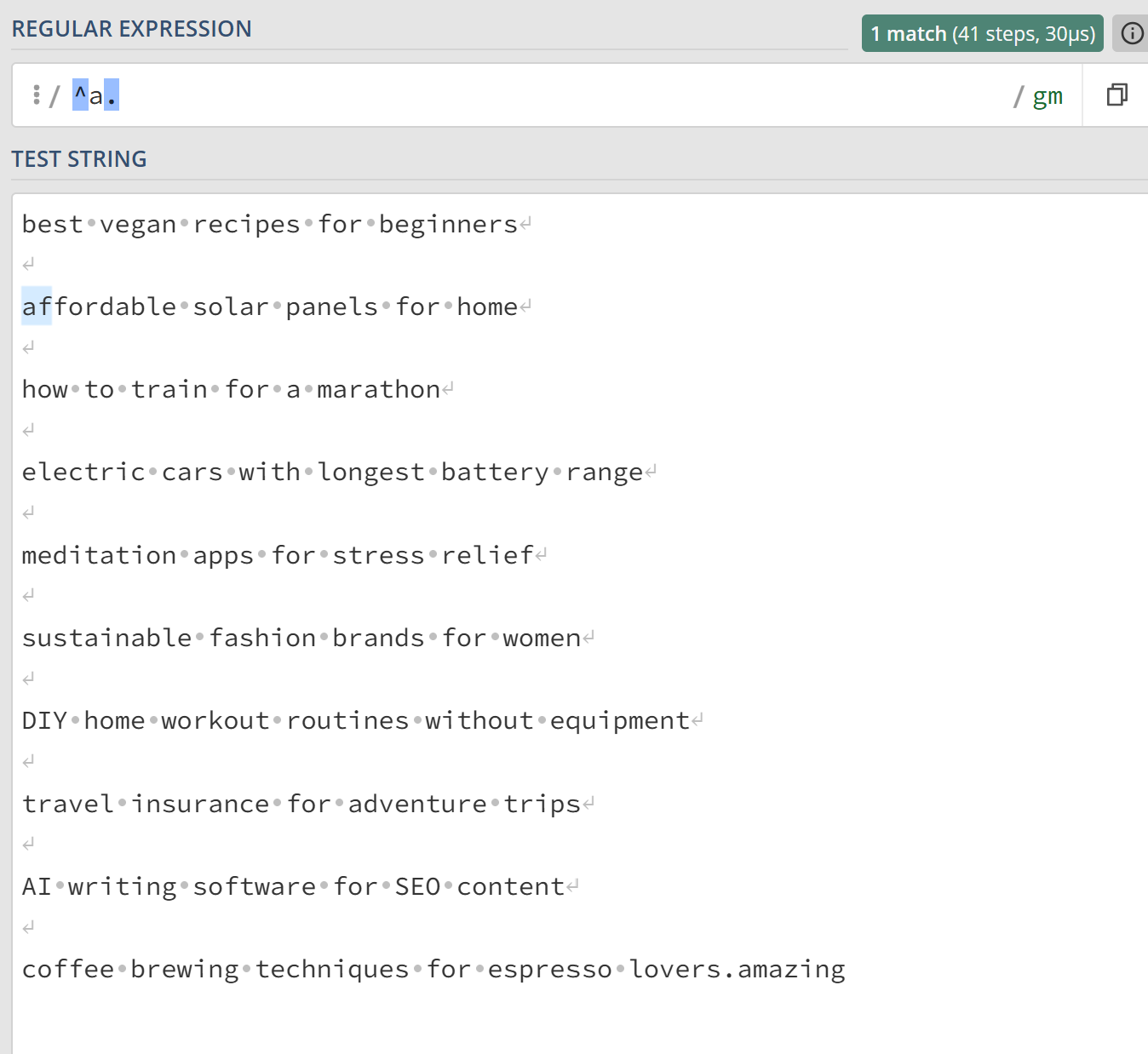
Example 3: Extract any string that starts with an “a” and ends with an “e” (i.e., any line that starts with a, followed by anything, then ends with an e).
- Regex:
^a.*e$ - Output: (All highlighted words in the screenshot below.)
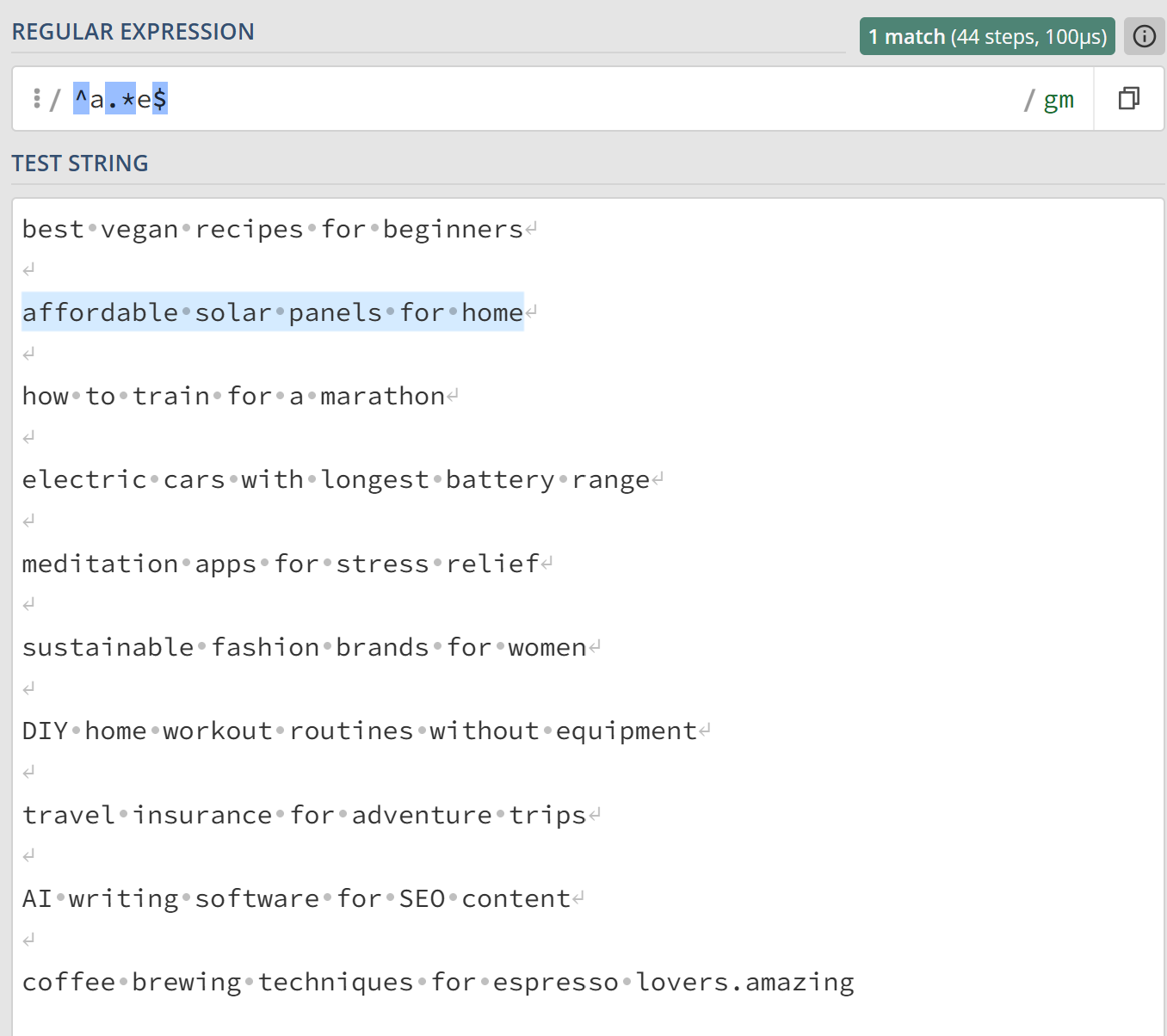
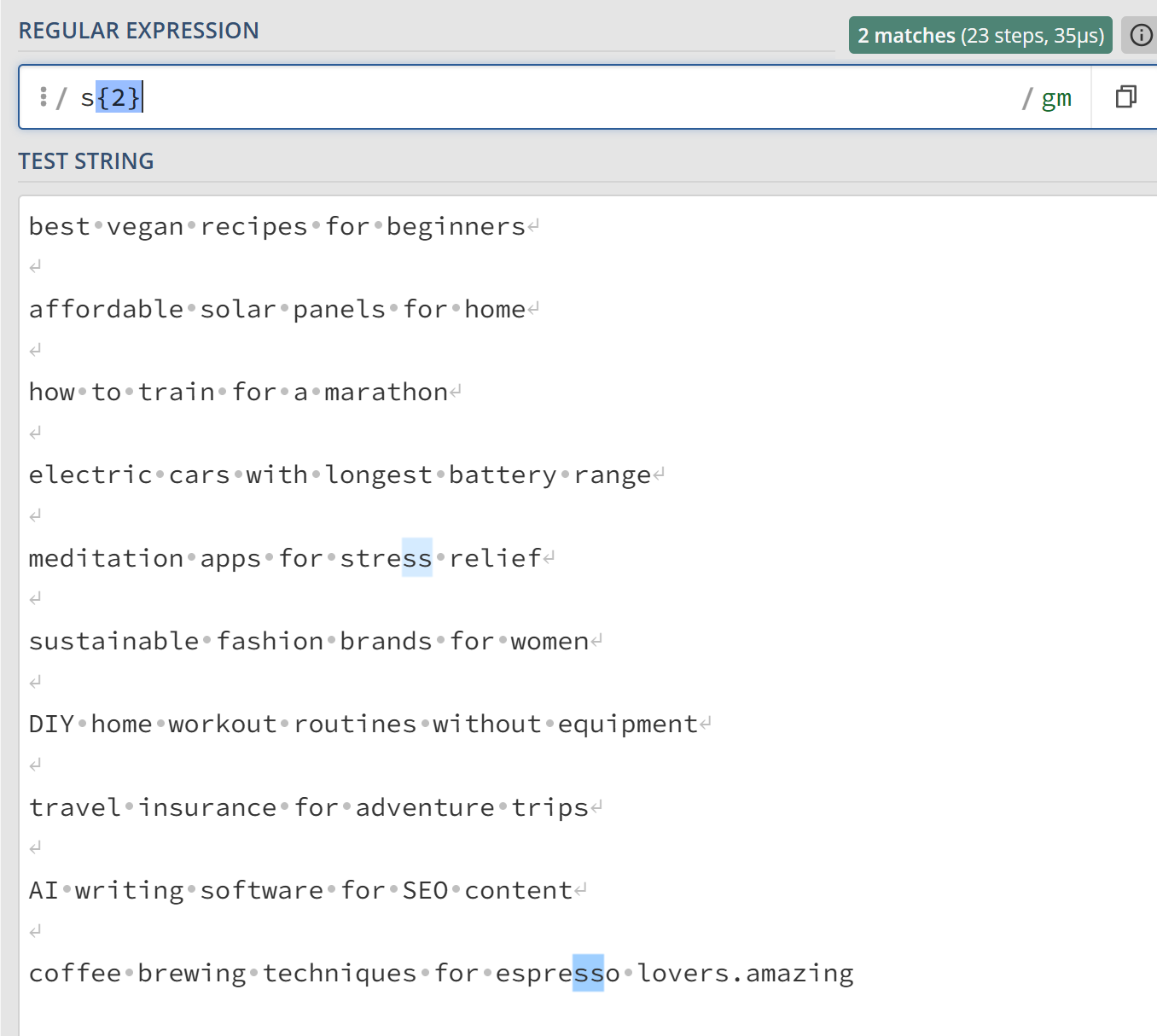
Example 4: Extract any string that contains two “s.”
- Regex:
s{2} - Output: (All highlighted words in the screenshot below.)
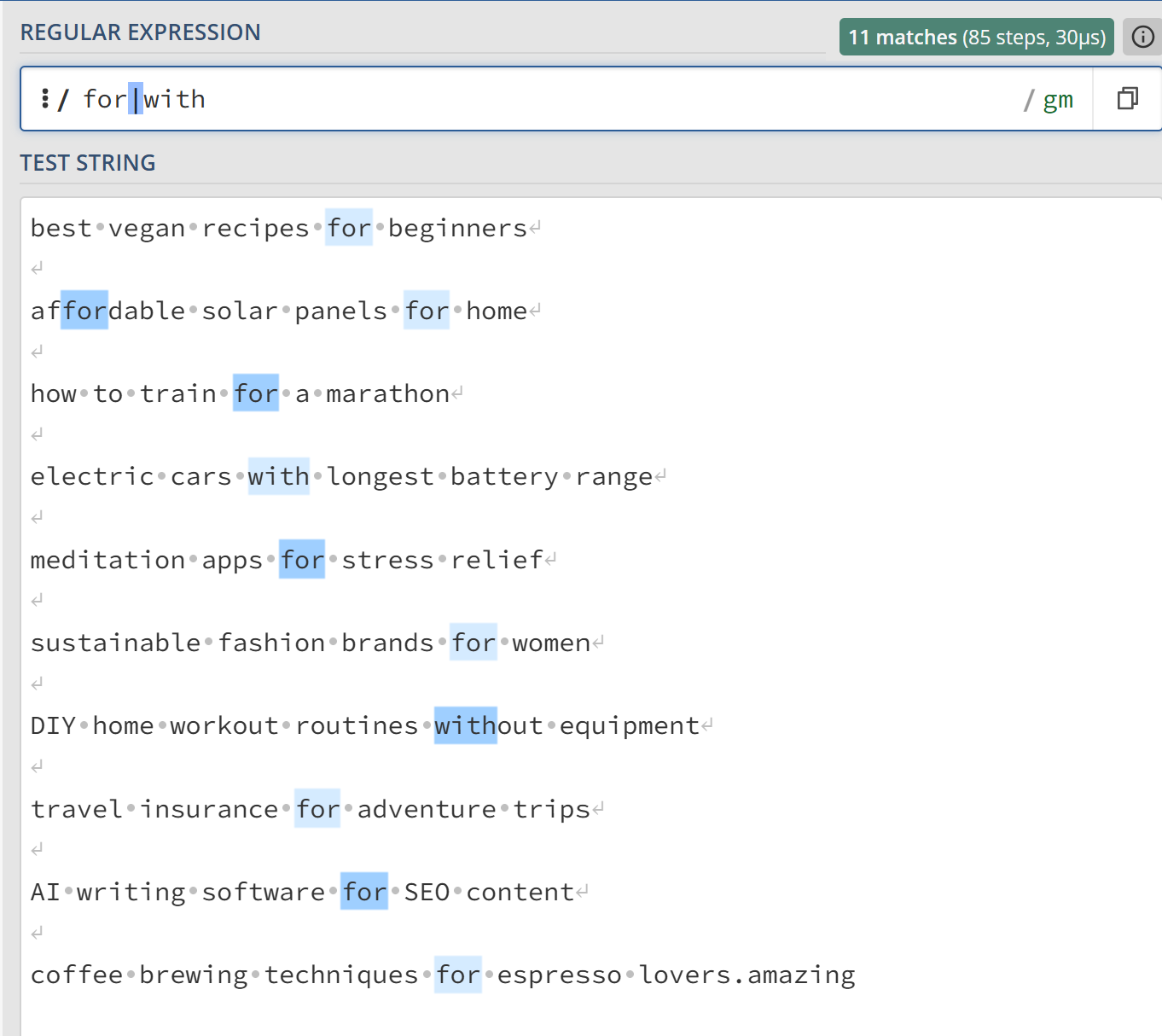
Example 5: Extract any string that contains “for” or “with.”
- Regex:
for|with - Output: (All highlighted words in the screenshot below.)
I’ve also built a sample regex Google Sheet so you can play around, test, and experience the feature in Google Sheets, too. Check it out here.
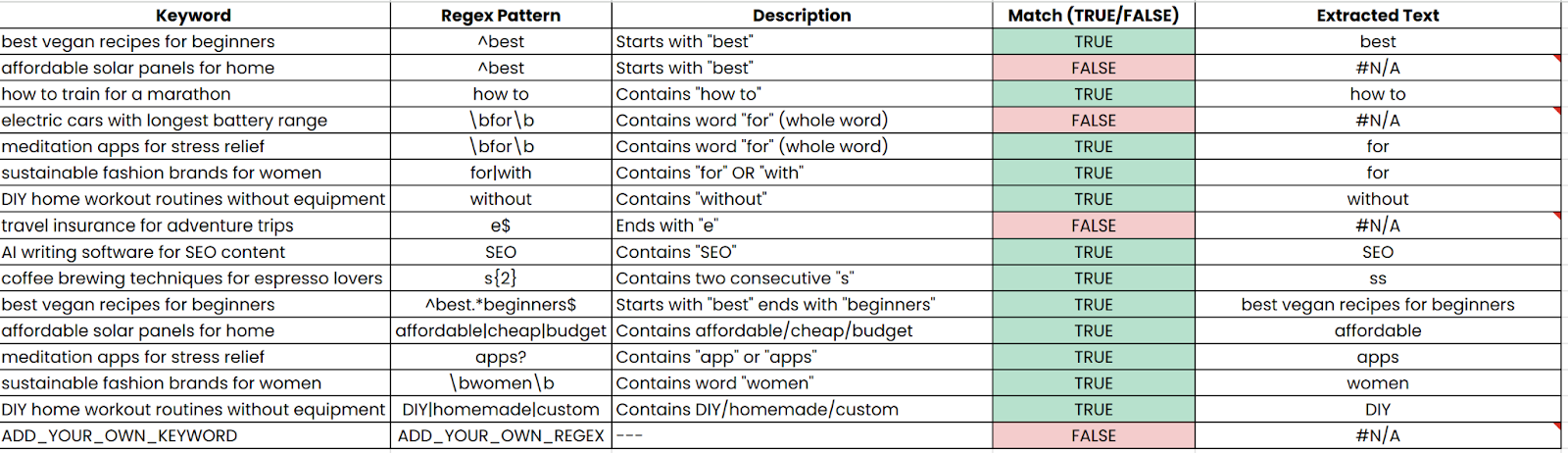
Note: Cells in the Extracted Text column showing #N/A indicate that the regex didn’t find a matching pattern.
Where regex fits in your SEO toolkit
By exploring regex, you’ll open new doors for analyzing and organizing search data.
It’s one of those skills that quietly makes you faster and more precise – whether you’re segmenting keywords, cleaning messy queries, or setting up advanced filters in Search Console or Looker Studio.
Once you’re comfortable with the basics, start spotting where regex can save you time.
Use it to identify branded versus nonbranded searches, group URLs by pattern, or validate large text datasets before they reach your reports.
Experiment with different expressions in tools like Regex101 or Google Sheets to see how small syntax changes affect results.
The more you practice, the easier it becomes to recognize patterns in both data and problem-solving.
That’s where regex truly earns its place in your SEO toolkit.




Recent Comments