

Why LLM-only pages aren’t the answer to AI search

With new updates in the search world stacking up in 2026, content teams are trying a new strategy to rank: LLM pages.
They’re building pages that no human will ever see: markdown files, stripped-down JSON feeds, and entire /ai/ versions of their articles.
The logic seems sound: if you make content easier for AI to parse, you’ll get more citations in ChatGPT, Perplexity, and Google’s AI Overviews.
Strip out the ads. Remove the navigation. Serve bots pure, clean text.
Industry experts such as Malte Landwehr have documented sites creating .md copies of every article or adding llms.txt files to guide AI crawlers.
Teams are even building entire shadow versions of their content libraries.
Google’s John Mueller isn’t buying it.
- “LLMs have trained on – read and parsed – normal web pages since the beginning,” he said in a recent discussion on Bluesky. “Why would they want to see a page that no user sees?”
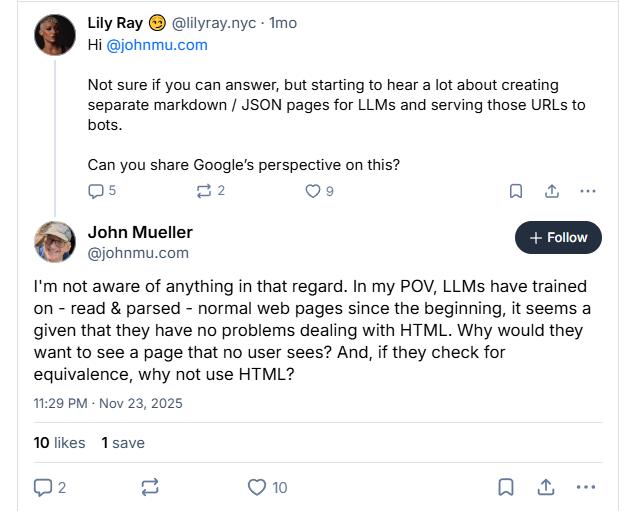
His comparison was blunt: LLM-only pages are like the old keywords meta tag. Available for anyone to use, but ignored by the systems they’re meant to influence.
So is this trend actually working, or is it just the latest SEO myth?
The rise of ‘LLM-only’ web pages
The trend is real. Sites across tech, SaaS, and documentation are implementing LLM-specific content formats.
The question isn’t whether adoption is happening, it’s whether these implementations are driving the AI citations teams hoped for.
Here’s what content and SEO teams are actually building.
llms.txt files
A markdown file at your domain root listing key pages for AI systems.
The format was introduced in 2024 by AI researcher Simon Willison to help AI systems discover and prioritize important content.
Plain text lives at yourdomain.com/llms.txt with an H1 project name, brief description, and organized sections linking to important pages.
Stripe’s implementation at docs.stripe.com/llms.txt shows the approach in action:
markdown# Stripe Documentation
> Build payment integrations with Stripe APIs
## Testing
- [Test mode](https://docs.stripe.com/testing): Simulate payments
## API Reference
- [API docs](https://docs.stripe.com/api): Complete API referenceThe payment processor’s bet is simple: if ChatGPT can parse their documentation cleanly, developers will get better answers when they ask, “how do I implement Stripe.”
They’re not alone. Current adopters include Cloudflare, Anthropic, Zapier, Perplexity, Coinbase, Supabase, and Vercel.
Markdown (.md) page copies
Sites are creating stripped-down markdown versions of their regular pages.
The implementation is straightforward: just add .md to any URL. Stripe’s docs.stripe.com/testing becomes docs.stripe.com/testing.md.
Everything gets stripped out except the actual content. No styling. No menus. No footers. No interactive elements. Just pure text and basic formatting.
The thinking: if AI systems don’t have to wade through CSS and JavaScript to find the information they need, they’re more likely to cite your page accurately.
/ai and similar paths
Some sites are building entirely separate versions of their content under /ai/, /llm/, or similar directories.
You might find /ai/about living alongside the regular /about page, or /llm/products as a bot-friendly alternative to the main product catalog.
Sometimes these pages have more detail than the originals. Sometimes they’re just reformatted.
The idea: give AI systems their own dedicated content that’s built for machine consumption, not human eyes.
If a person accidentally lands on one of these pages, they’ll find something that looks like a website from 2005.
JSON metadata files
Dell took this approach with their product specs.
Instead of creating separate pages, they built structured data feeds that live alongside their regular ecommerce site.
The files contain clean JSON – specs, pricing, and availability.
Everything an AI needs to answer “what’s the best Dell laptop under $1000” without having to parse through product descriptions written for humans.
You’ll typically find these files as /llm-metadata.json or /ai-feed.json in the site’s directory.
# Dell Technologies
> Dell Technologies is a leading technology provider, specializing in PCs, servers, and IT solutions for businesses and consumers.
## Product and Catalog Data
- [Product Feed - US Store](https://www.dell.com/data/us/catalog/products.json): Key product attributes and availability.
- [Dell Return Policy](https://www.dell.com/return-policy.md): Standard return and warranty information.
## Support and Documentation
- [Knowledge Base](https://www.dell.com/support/knowledge-base.md): Troubleshooting guides and FAQs.This approach makes the most sense for ecommerce and SaaS companies that already keep their product data in databases.
They’re just exposing what they already have in a format AI systems can easily digest.
Dig deeper: LLM optimization in 2026: Tracking, visibility, and what’s next for AI discovery
Real-world citation data: What actually gets referenced
The theory sounds good. The adoption numbers look impressive.
But do these LLM-optimized pages actually get cited?
The individual analysis
Landwehr, CPO and CMO at Peec AI, ran targeted tests on five websites using these tactics. He crafted prompts specifically designed to surface their LLM-friendly content.
Some queries even contained explicit 20+ word quotes designed to trigger specific sources.
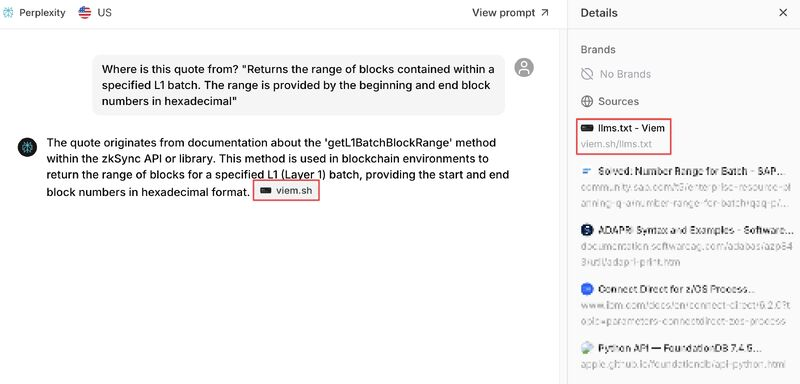
Across nearly 18,000 citations, here’s what he found.
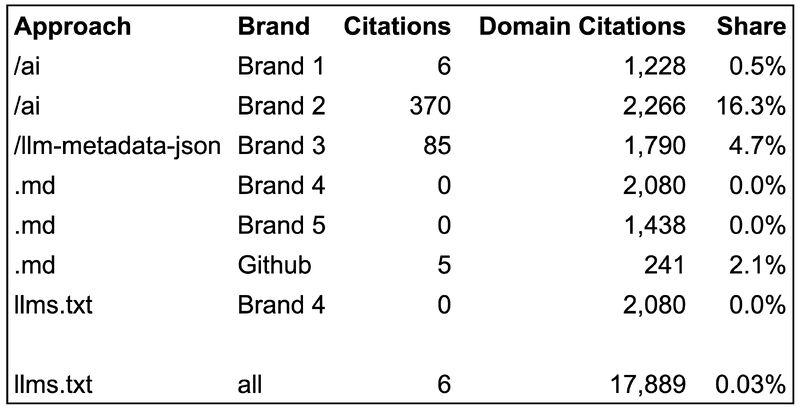
llms.txt: 0.03% of citations
Out of 18,000 citations, only six pointed to llms.txt files.
The six that did work had something in common: they contained genuinely useful information about how to use an API and where to find additional documentation.
The kind of content that actually helps AI systems answer technical questions. The “search-optimized” llms.txt files, the ones stuffed with content and keywords, received zero citations.
Markdown (.md) pages: 0% of citations
Sites using .md copies of their content got cited 3,500+ times. None of those citations pointed to the markdown versions.
The one exception: GitHub, where .md files are the standard URLs.
They’re linked internally, and there’s no HTML alternative. But these are just regular pages that happen to be in markdown format.
/ai pages: 0.5% to 16% of citations
Results varied wildly depending on implementation.
One site saw 0.5% of its citations point to its/ai pages. Another hit 16%.
The difference?
The higher-performing site put significantly more information in their /ai pages than existed anywhere else on their site.
Keep in mind, these prompts were specifically asking for information contained in these files.
Even with prompts designed to surface this content, most queries ignored the /ai versions.
JSON metadata: 5% of citations
One brand saw 85 out of 1,800 citations (5%) come from their metadata JSON file.
The critical detail here is that the file contained information that didn’t exist anywhere else on the website.
Once again, the query specifically asked for those pieces of information.

The large-scale analysis
SE Ranking took a different approach.
Instead of testing individual sites, they analyzed 300,000 domains to see if llms.txt adoption correlated with citation frequency at scale.
Only 10.13% of domains, or 1 in 10, had implemented llms.txt.
For context, that’s nowhere near the universal adoption of standards like robots.txt or XML sitemaps.
During the study, an interesting relationship between adoption rates and traffic levels emerged.
Sites with 0-100 monthly visits adopted llms.txt at 9.88%.
Sites with 100,001+ visits? Just 8.27%.
The biggest, most established sites were actually slightly less likely to use the file than mid-tier ones.
But the real test was whether llms.txt impacted citations.
SE Ranking built a machine learning model using XGBoost to predict citation frequency based on various factors, including the presence of llms.txt.
The result: removing llms.txt from the model actually improved its accuracy.
The file wasn’t helping predict citation behavior, it was adding noise.
The pattern
Both analyses point to the same conclusion: LLM-optimized pages get cited when they contain unique, useful information that doesn’t exist elsewhere on your site.
The format doesn’t matter.
Landwehr’s conclusion was blunt: “You could create a 12345.txt file and it would be cited if it contains useful and unique information.”
A well-structured about page achieves the same result as an /ai/about page. API documentation gets cited whether it’s in llms.txt or buried in your regular docs.
The files themselves get no special treatment from AI systems.
The content inside them might, but only if it’s actually better than what already exists on your regular pages.
SE Ranking’s data backs this up at scale. There’s no correlation between having llms.txt and getting more citations.
The presence of the file made no measurable difference in how AI systems referenced domains.
Dig deeper: 7 hard truths about measuring AI visibility and GEO performance
What Google and AI platforms actually say
No major AI company has confirmed using llms.txt files in their crawling or citation processes.
Google’s Mueller made the sharpest critique in April 2025, comparing llms.txt to the obsolete keywords meta tag:
- “[As far as I know], none of the AI services have said they’re using LLMs.TXT (and you can tell when you look at your server logs that they don’t even check for it).”
Google’s Gary Illyes reinforced this at the July 2025 Search Central Deep Dive in Bangkok, explicitly stating Google “doesn’t support LLMs.txt and isn’t planning to.”
Google Search Central’s documentation is equally clear:
- “The best practices for SEO remain relevant for AI features in Google Search. There are no additional requirements to appear in AI Overviews or AI Mode, nor other special optimizations necessary.”
OpenAI, Anthropic, and Perplexity all maintain their own llms.txt files for their API documentation to make it easy for developers to load into AI assistants.
But none have announced their crawlers actually read these files from other websites.
The consistent message from every major platform: standard web publishing practices drive visibility in AI search.
No special files, no new markup, and no separate versions needed.
What this means for SEO teams
The evidence points to a single conclusion: stop building content that only machines will see.
Mueller’s question cuts to the core issue:
- “Why would they want to see a page that no user sees?”
If AI companies needed special formats to generate better responses, they would tell you. As he noted:
- “AI companies aren’t really known for being shy.”
The data proves him right.
Across Landwehr’s nearly 18,000 citations, LLM-optimized formats showed no advantage unless they contained unique information that didn’t exist anywhere else on the site.
SE Ranking’s analysis of 300,000 domains found that llms.txt actually added confusion to their citation prediction model rather than improving it.
Instead of creating shadow versions of your content, focus on what actually works.
Build clean HTML that both humans and AI can parse easily.
Reduce JavaScript dependencies for critical content, which Mueller identified as the real technical barrier:
- “Excluding JS, which still seems hard for many of these systems.”
Heavy client-side rendering creates actual problems for AI parsing.
Use structured data when platforms have published official specifications, such as OpenAI’s ecommerce product feeds.
Improve your information architecture so key content is discoverable and well-organized.
The best page for AI citation is the same page that works for users: well-structured, clearly written, and technically sound.
Until AI companies publish formal requirements stating otherwise, that’s where your optimization energy belongs.
Dig deeper: GEO myths: This article may contain lies





Recent Comments