

New web standards could redefine how AI models use your content

In recent years, the open web has felt like the Wild West. Creators have seen their work scraped, processed, and fed into large language models – mostly without their consent.
It became a data free-for-all, with almost no way for site owners to opt out or protect their work.
There have been efforts, like llms.txt initiative from Jeremy Howard. Like robots.txt, which lets site owners allow or block site crawlers, llms.txt offers rules that do the same for AI companies’ crawling bots.
But there’s no clear evidence that AI companies follow llms.txt or honor its rules. Plus, Google explicitly said it doesn’t support llms.txt.
However, a new protocol is now emerging to give site owners control over how AI companies use their content. It may become part of robots.txt, allowing owners to set clear rules for how AI systems can access and use their sites.
IETF AI Preferences Working Group
To address this, the Internet Engineering Task Force (IETF) launched the AI Preferences Working Group in January. The group is creating standardized, machine-readable rules that let site owners spell out how (or if) AI systems can use their content.
Since its founding in 1986, the IETF has defined the core protocols that power the Internet, including TCP/IP, HTTP, DNS, and TLS.
Now they’re developing standards for the AI era of the open web. The AI Preferences Working Group is co-chaired by Mark Nottingham and Suresh Krishnan, along with leaders from Google, Microsoft, Meta, and others.
Notably, Google’s Gary Illyes is also part of the working group.
The goal of this group:
- “The AI Preferences Working Group will standardize building blocks that allow for the expression of preferences about how content is collected and processed for Artificial Intelligence (AI) model development, deployment, and use.”
What the AI Preferences Group is proposing
This working group will deliver new standards that give site owners control over how LLM-powered systems use their content on the open web.
- A standard track document covering vocabulary for expressing AI-related preferences, independent of how those preferences are associated with content.
- Standard track document(s) describing means of attaching or associating those preferences with content in IETF-defined protocols and formats, including but not limited to using Well-Known URIs (RFC 8615) such as the Robots Exclusion Protocol (RFC 9309), and HTTP response header fields.
- A standard method for reconciling multiple expressions of preferences.
As of this writing, nothing from the group is final yet. But they have published early documents that offer a glimpse into what the standards might look like.
Two main documents were published by this working group in August.
- A Vocabulary For Expressing AI Usage Preferences
- Associating AI Usage Preferences with Content in HTTP (Illyes is one of the authors of this document)
Together, these documents propose updates to the existing Robots Exclusion Protocol (RFC 9309), adding new rules and definitions that let site owners spell out how they want AI systems to use their content on the web.
How it might work
Different AI systems on the web are categorized and given standard labels. It’s still unclear whether there will be a directory where site owners can look up how each system is labeled.
These are the labels defined so far:
- search: for indexing/discoverability
- train-ai: for general AI training
- train-genai: for generative AI model training
- bots: for all forms of automated processing (including crawling/scraping)
For each of these labels, two values can be set:
- y to allow
- n to disallow.
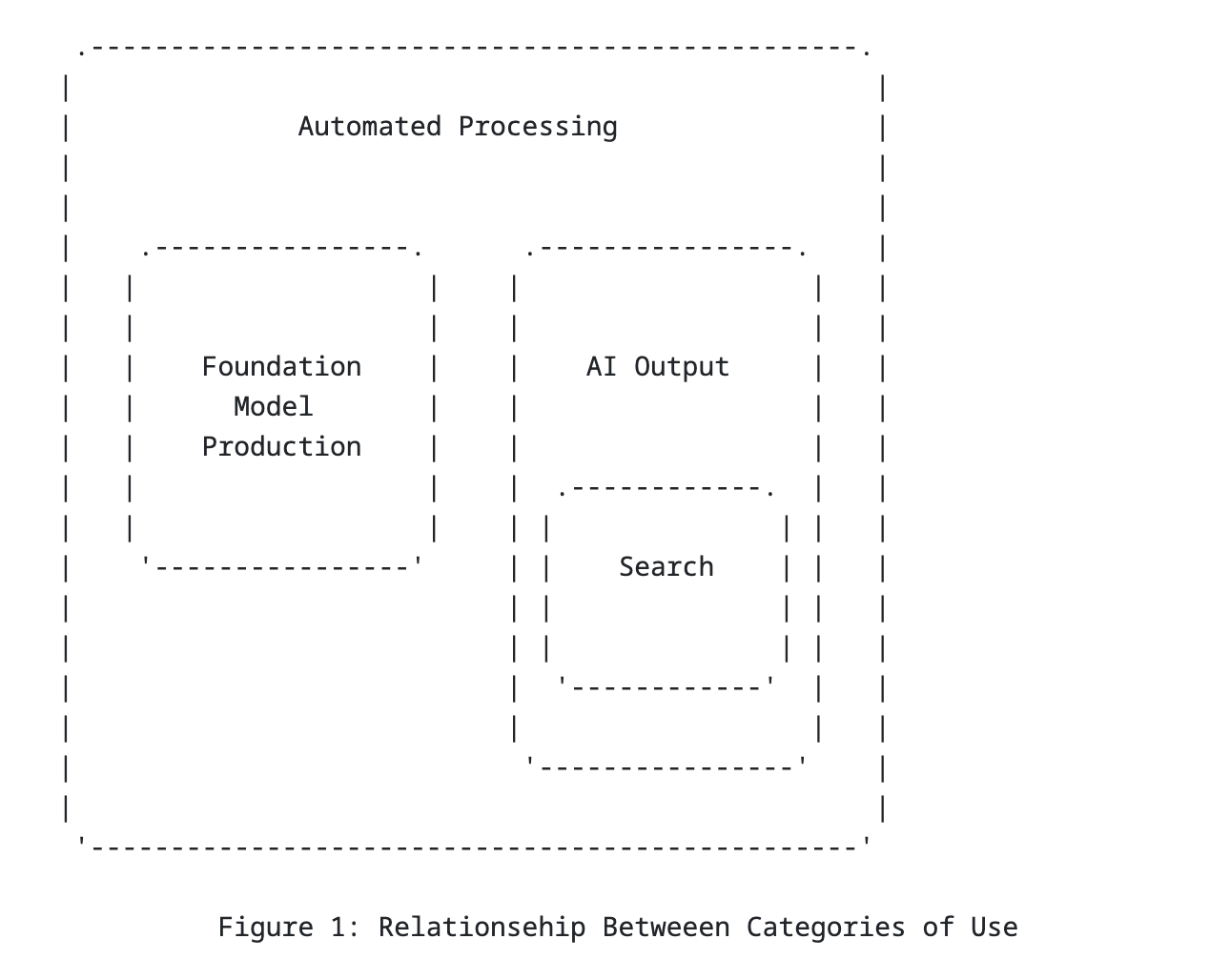
The documents also note that these rules can be set at the folder level and customized for different bots. In robots.txt, they’re applied through a new Content-Usage field, similar to how the Allow and Disallow fields work today.
Here is an example robots.txt that the working group included in the document:
User-Agent: *
Allow: /
Disallow: /never/
Content-Usage: train-ai=n
Content-Usage: /ai-ok/ train-ai=y
Explanation
Content-Usage: train-ai=n means all the content on this domain isn’t allowed for training any LLM model while Content-Usage: /ai-ok/ train-ai=y specifically means that training the models using content of subfolder /ai-ok/ is alright.
Why does this matter?
There’s been a lot of buzz in the SEO world about llms.txt and why site owners should use it alongside robots.txt, but no AI company has confirmed that their crawlers actually follow its rules. And we know Google doesn’t use llms.txt.
Still, site owners want clearer control over how AI companies use their content – whether for training models or powering RAG-based answers.
IETF’s work on these new standards feels like a step in the right direction. And with Illyes involved as an author, I’m hopeful that once the standards are finalized, Google and other tech companies will adopt them and respect the new robots.txt rules when scraping content.




Recent Comments