

Generative AI and defamation: What the new reputation threats look like

As generative AI becomes more embedded in search and content experiences, it’s also emerging as a new source of misinformation and reputational harm.
False or misleading statements generated by AI chatbots are already prompting legal disputes – and raising fresh questions about liability, accuracy, and online reputation management.
When AI becomes the source of defamation
It’s unsurprising that AI has become a new source of defamation and online reputation damage.
As an SEO and reputation expert witness, I’ve already been approached by litigants involved in cases where AI systems produced libelous statements.
This is uncharted territory – and while solutions are emerging, much of it remains new ground.
Real-world examples of AI-generated defamation
One client contacted me after Meta’s Llama AI generated false, misleading, and defamatory statements about a prominent individual.
Early research showed that the person had been involved in – and prevailed in – previous defamation lawsuits, which had been reported by news outlets.
Some detractors had also criticized the individual online, and discussions on Reddit included inaccurate and inflammatory language.
Yet when the AI was asked about the person or their reputation, it repeated those vanquished claims, added new warnings, and projected assertions of fraud and untrustworthiness.
In another case, a client targeted by defamatory blog posts found that nearly any prompt about them in ChatGPT surfaced the same false claims.
The key concern: even if the court orders the original posts removed, how long will those defamatory statements persist in AI responses?
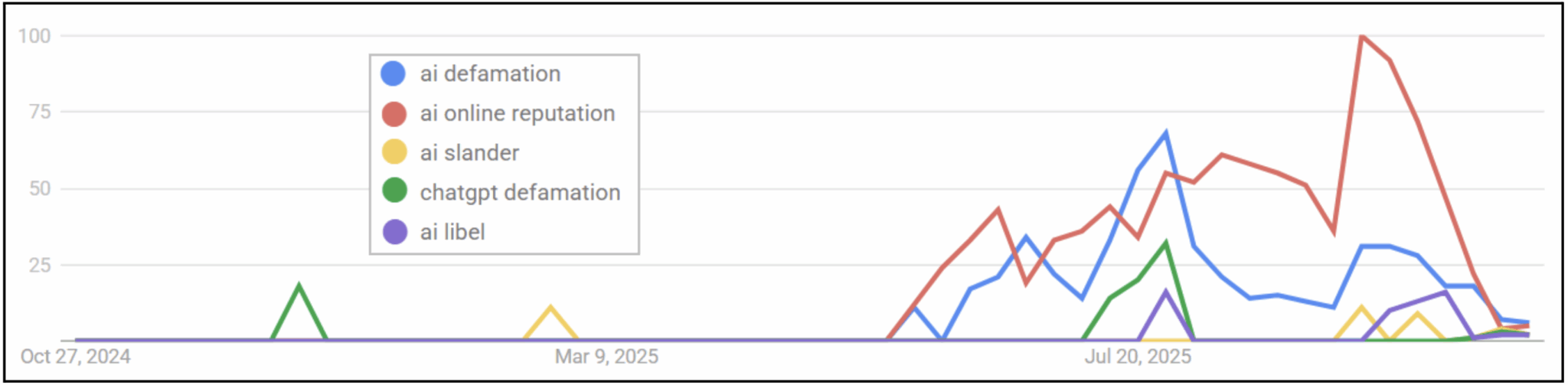
Google Trends shows that there has been a significant spike in searches related to defamation communicated via AI chatbots and AI-related online reputation management:
Fabricated stories and real-world harm
In other cases revealed by lawsuit filings, generative AI has apparently fabricated entirely false and damaging content about people out of thin air.
In 2023, Jonathan Turley, the Shapiro Professor of Public Interest Law at George Washington University, was falsely reported to have been accused of sexual harassment – a claim that was never made, on a trip that never happened, while he was at a faculty where he never taught.
ChatGPT cited a Washington Post article that was never written as its source.
In September, former FBI operative James Keene filed a lawsuit against Google after its AI falsely claimed he was serving a life sentence for multiple convictions and described him as the murderer of three women.
The suit also alleges that these false statements were potentially seen by tens of millions of searchers.
Generative AI can fabricate stories about people – that’s the “generative” part of “generative AI.”
After receiving a prompt, an AI chatbot analyzes the input and produces a response based on patterns learned from large volumes of text.
So it’s no surprise that AI answers have at times included false and defamatory content about individuals.
Improvements and remaining challenges
Over the past two years, AI chatbots have shown improvement in handling biographical information about individuals.
The most prominent chatbot companies seem to have focused on refining their systems to better manage queries involving people and proper names.
As a result, the generation of false information – or hallucinations – about individuals seems to have declined significantly.
AI chat providers have also begun incorporating more disclaimer language into responses about people’s biographical details and reputations.
These often include statements noting:
- Limited information.
- Uncertainty about a person’s identity.
- The lack of independent verification.
It’s unclear how much such disclaimers actually protect against false or damaging assertions, but they are at least preferable to providing no warning at all.
In one instance, a client who was allegedly defamed by Meta’s AI had their counsel contact the company directly.
Meta reportedly moved quickly to address the issue – and may have even apologized, which is nearly unheard of in matters of corporate civil liability.
At this stage, the greatest reputational risks from AI are less about outright fabrications.
The more pressing threats come from AI systems:
- Misconstruing source material to draw inaccurate conclusions.
- Repeating others’ defamatory claims.
- Exaggerating and distorting true facts in misleading ways.
Legal liability and Section 230
Because the law around AI-generated libel is still rapidly developing, there is little legal precedent defining how liable companies might be for defamatory statements produced by their AI chatbots.
Some argue that Section 230 of the Communications Decency Act could shield AI companies from such liability.
The reasoning is that if online platforms are largely immune from defamation claims for third-party content they host, then AI systems should be similarly protected since their outputs are derived from third-party sources.
However, derived is far from quoted or reproduced – it implies a meaningful degree of originality.
If legislators already believed AI output was protected under Section 230, they likely would not have proposed a 10-year moratorium on enforcing state or local restrictions on artificial intelligence models, systems, and decision-making processes.
That moratorium was initially included in President Trump’s budget reconciliation bill, H.R.1 – nicknamed the “One Big Beautiful Bill Act” – but was ultimately dropped when the law was signed on July 4, 2025.
Get the newsletter search marketers rely on.
See terms.
AI’s growing role in reputation management
The rising prominence of AI-generated answers – such as Google’s AI Overviews – is making information about people’s backgrounds and reputations both more visible and more influential.
As these systems become increasingly accurate and dependable, it’s not a stretch to say that the public will be more inclined to believe what AI says about someone – even when that information is false, misleading, or defamatory.
AI is also playing a larger role in background checks.
For example, Checkr has developed a custom AI that searches for and surfaces potentially negative or defamatory information about individuals – findings that could limit a person’s employment opportunities with companies using the service.
While major AI providers such as Google, OpenAI, Microsoft, and Meta have implemented guardrails to reduce the spread of defamation, services like Checkr are less likely to include caveats or disclaimers.
Any defamatory content generated by such systems may therefore go unnoticed by those it affects.
At present, AI is most likely to produce defamatory statements when the web already contains defamatory pages or documents.
Removing those source materials usually corrects or eliminates the false information from AI outputs.
But as AI systems increasingly “remember” prior responses – or cache information to save on processing – removing the original sources may no longer be enough to erase defamatory or erroneous claims from AI-generated answers.
What can be done about AI defamation?
One key way to address defamation appearing in AI platforms is to ask them directly to correct or remove false and damaging statements about you.
As noted above, some platforms – such as Meta – have already taken action to remove content that appeared libelous.
(Ironically, it may now be easier to get Meta to delete harmful material from its Llama AI than from Facebook.)
These companies may be more responsive if the request comes from an attorney, though they also appear willing to act on reports submitted by individuals.
Here’s how to contact each major AI provider to request the removal of defamatory content:
Meta Llama
Use the Llama Developer Feedback Form or email LlamaUseReport@meta.com to report or request removal of false or defamatory content.
ChatGPT
In ChatGPT, you can report problematic content directly within the chat interface.
On desktop, click the three dots in the upper-right corner and select Report from the dropdown menu.
On mobile or other devices, the option may appear under a different menu.

AI Overviews and Gemini
There are two ways to report content to Google.
You can report content for legal reasons. (Click See more options to select Gemini, or within the Gemini desktop interface, use the three dots below a response.)
However, Google typically won’t remove content through this route unless you have a court order, since it cannot determine whether material is defamatory.
Alternatively, you can send feedback directly.
For AI Overviews, click the three dots on the right side of the result and choose Feedback.
From Gemini, click the thumbs-down icon and complete the feedback form.
While this approach may take time, Google has previously reduced visibility of harmful or misleading information through mild suppression – similar to its approach with Autocomplete.
When submitting feedback, explain that:
- You are not a public figure.
- The AI Overview unfairly highlights negative material.
- You would appreciate Google limiting its display even if the source pages remain online.
Bing AI Overview and Microsoft Copilot
As with Google, you can either send feedback or report a concern.
In Bing search results, click the thumbs-down icon beneath an AI Overview to begin the feedback process.
In the Copilot chatbot interface, click the thumbs-down icon below the AI-generated response.
When submitting feedback, describe clearly – and politely – how the content about you is inaccurate or harmful.
For legal removal requests, use Microsoft’s Report a Concern form.
However, this route is unlikely to succeed without a court order declaring the content illegal or defamatory.
Perplexity
To request the removal of information about yourself from Perplexity AI, email support@perplexity.ai with the relevant details.
Grok AI
You can report an issue within Grok by clicking the three dots below a response. Legal issues can also be reported through xAI.
According to xAI’s privacy policy:
- “Please note that we cannot guarantee the factual accuracy of Output from our models. If Output contains factually inaccurate personal information relating to you, you can submit a correction request and we will make reasonable efforts to correct this information – but due to the technical complexity of our models, it may not be feasible for us to do so.”
To submit a correction request, go to https://xai-privacy.relyance.ai/.
Additional approaches to addressing reputation damage in AI
If contacting AI providers doesn’t fully resolve the issue, there are other steps you can take to limit or counteract the spread of false or damaging information.
Remove negative content from originating sources
Outside of the decreasing instances of defamatory or damaging statements produced by AI hallucinations, most harmful content is gathered or summarized from existing online sources.
Work to remove or modify those sources to make it less likely that AIs will surface them in responses.
Persuasion is the first step, where possible. For example:
- Add a statement to a news article acknowledging factual errors.
- Note that a court has ruled the content false or defamatory.
These can trigger AI guardrails that prevent the material from being repeated.
Disclaimers or retractions may also stop AI systems from reproducing negative information.
Overwhelm AI with positive and neutral information
Evidence suggests that AIs are influenced by the volume of consistent information available.
Publishing enough accurate, positive, or neutral material about a person can shift what an AI considers reliable.
If most sources reflect the same biographical details, AI models may favor those over isolated negative claims.
However, the new content must appear on reputable sites that are equal to or superior in authority to where the negative material was published – a challenge when the harmful content originates from major news outlets, government websites, or other credible domains.
Displace the negative information in the search engine results
Major AI chatbots source some of their information from search engines.
Based on my testing, the complexity of the query determines how many results an AI may reference, ranging from the first 10 listings to several dozen or more.
The implication is clear: if you can push negative results further down in search rankings – beyond where the AI typically looks – those items are less likely to appear in AI-generated responses.
This is a classic online reputation management method: utilizing standard SEO techniques and a network of online assets to displace negative content in search results.
However, AI has added a new layer of difficulty.
ORM professionals now need to determine how far back each AI model scans results to answer questions about a person or topic.
Only then can they know how far the damaging results must be pushed to “clean up” AI responses.
In the past, pushing negative content off the first one or two pages of search results provided about 99% relief from its impact.
Today, that’s often not enough.
AI systems may pull from much deeper in the search index – meaning ORM specialists must suppress harmful content across a wider range of pages and related queries.
Because AI can conduct multiple, semantically related searches when forming answers, it’s essential to test various keyword combinations and clear negative items across all relevant SERPs.
Obfuscate by launching personas that share the same name
Using personas that “coincidentally” share the same name as someone experiencing reputation problems has long been an occasional, last-resort strategy.
It’s most relevant for individuals who are uncomfortable creating more online media about themselves – even when doing so could help counteract unfair, misleading, or defamatory content.
Ironically, that reluctance often contributes to the problem: a weak online presence makes it easier for someone’s reputation to be damaged.
When a name is shared by multiple individuals, AI chatbots appear to tread more carefully, often avoiding specific statements when they can’t determine who the information refers to.
This tendency can be leveraged.
By creating several well-developed online personas with the same name – complete with legitimate-seeming digital footprints – it’s possible to make AIs less certain about which person is being referenced.
That uncertainty can prevent them from surfacing or repeating defamatory material.
This method is not without complications.
People increasingly use both AI and traditional search tools to find personal information, so adding new identities risks confusion or unintended exposure.
Still, in certain cases, “clouding the waters” with credible alternate personas can be a practical way to reduce or dilute defamatory associations in AI-generated responses.
Old laws, new risks
A hybrid approach combining the methods described above may be necessary to mitigate the harm experienced by victims of AI-related defamation.
Some forms of defamation have always been difficult – and sometimes impossible – to address through lawsuits.
Litigation is expensive and can take months or years to yield relief.
In some cases, pursuing a lawsuit is further complicated by professional or legal constraints.
For example, a doctor seeking to sue a patient over defamatory statements could violate HIPAA by disclosing identifying information, and attorneys may face similar challenges under their respective bar association ethics rules.
There’s also the risk that defamation long buried in search results – or barred from litigation by statutes of limitation – could suddenly resurface through AI chatbot responses.
It may eventually lead to interesting case law, arguing that an AI-generated response constitutes a “new publication” of defamatory content, potentially resetting the limitations on those claims.
Another possible solution, albeit a distant one, would be to advocate for new legislation that protects individuals from negative or false information disseminated through AI systems.
Other regions, such as Europe, have established privacy laws, including the “Right to be Forgotten,” that give individuals more control over their personal information.
Similar protections would be valuable in the United States, but they remain unlikely given the enduring force of Section 230, which continues to shield large tech companies from liability for online content.
AI-driven reputational harm remains a rapidly evolving field – legally, technologically, and strategically.
Expect further developments ahead as courts, lawmakers, and technologists continue to grapple with this emerging frontier.




Recent Comments