

Optimizing for AI: How search engines power ChatGPT, Gemini and more

How do you optimize to have content featured in AI?
Whether it’s ChatGPT, Google Gemini, Meta’s LLaMa, Grok, Microsoft’s Claude, or Perplexity AI, the challenge is understanding how these systems access, consume, and deliver answers from live documents on the web.
If you follow digital marketing and SEO conversations on social media, you’ll know how quickly AI optimization advice has surged in popularity.
Google Trends shows interest rising steadily over the past couple of years – now spiking sharply.
The term “AI SEO” appears to be winning the naming-convention debate for this niche, with “generative engine optimization” also gaining traction.
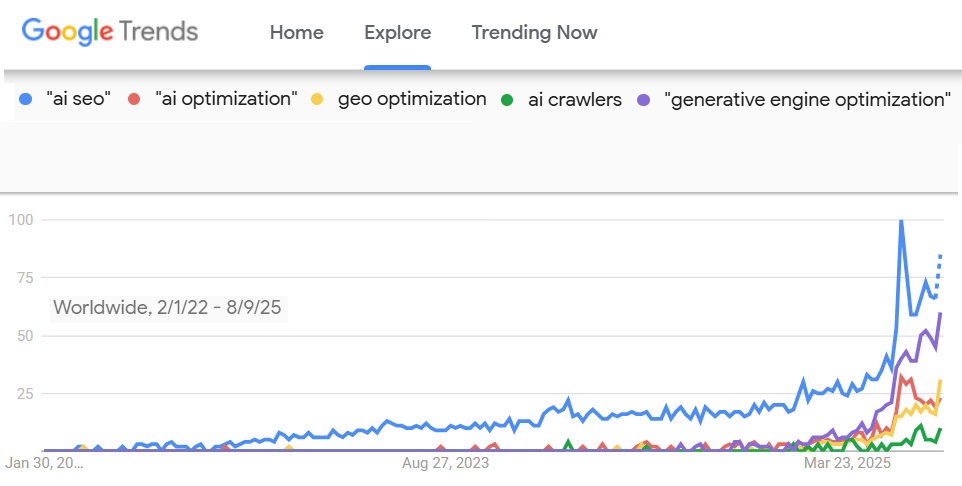
The rise of AI optimization
When generative AI burst on the scene, it was quickly followed by conjecture about the death of SEO.
But such claims rest on a naive view of how generative AI works, shaped by science fiction portrayals.
In those stories, AI is an intelligent agent that produces answers on its own or flawlessly curates the entirety of human knowledge.
In reality, AI is fed on information, and one of its primary contemporary sources is the web and the websites that compose it.
Simply put, SEO feeds AI.
Google Gemini as a case study
One could argue that optimization unique to AI is unnecessary or redundant, since in some cases – such as Google’s Gemini – AI already pulls content and answers from the top-ranking webpages for a query.
Google co-founder Sergey Brin describes this as the AI retrieving the top thousand search results, then running follow-on searches to refine and analyze them.
This is exactly how part of Google’s AI works.
For instance, if I search in Google AI Mode for something that needs fresh information, such as “what are the current-most promising experimental treatments for melanoma?”, the system follows a multi-step process:
First, a broad search gathers a wide range of information.
Then, it narrows down to the most relevant and reliable sources to construct an answer.
Submitting that phrase to Google Gemini – the AI powering Google’s AI Mode results – triggers a rapid countdown of hundreds of sites identified behind the scenes as relevant to the query.
From broad to refined queries
The initial broad queries were identified for a range of potential treatments and medical studies, including:
- “Experimental treatments for melanoma.”
- “Novel therapies melanoma.”
- “Melanoma clinical trials promising.”
- “Future melanoma treatments.”
Does this not seem like the sorts of keyword phrases one would uncover if conducting keyword research around the initial search query about promising experimental treatments for melanoma?
It definitely is – Google’s AI Mode is initially conducting an identification of closely related search phrases.
After it came up with these multiple, broad queries, Google’s AI Mode conducts searches with each of them, just as a human researcher seeking information might do.
AI Mode is using Google Search itself to conduct this query.
The webpages coming up high in the search results for each of these queries are the sources for the information it analyzes before answering the submitted question.
From those broad results, Gemini conducted more refined queries based on lines of inquiry it developed from the first stage of results.
These refinement queries included:
- “TIL therapy melanoma clinical trials.”
- “Oncolytic virus melanoma treatment.”
- “BiTEs melanoma.”
- “mRNA vaccine melanoma.”
- “Lifileucel melanoma.”
- “T-VEC melanoma.”
- “Tebentafusp melanoma uveal.”
- “V940 melanoma clinical trial.”
It conducts further queries indicated by the research and pulls back webpages based on those as well.
This process, which they refer to as “fanning out,” identifies a tree of related queries to identify all the sources of information it considers in answering queries.
Dig deeper: Chunks, passages and micro-answer engine optimization wins in Google AI Mode
Authority and reliability in AI answers
Of the webpages it reviews, either through the search process or after obtaining all relevant pages, it then identifies reliable and authoritative sources based on E-E-A-T criteria.
For this sort of query, Google will likely consider it in the important category of Your Money or Your Life (YMYL).
It is unsurprising that Gemini used the websites of:
- Reputable medical institutions (e.g., universities, cancer centers).
- Government health agencies (e.g., NIH, FDA).
- Organizations dedicated to melanoma research and advocacy.
- Peer-reviewed scientific publications.
Right now, with Google’s AI Mode, you really don’t need to change a thing. Just keep doing what you’d normally do to appear in Google’s search results.
Performing SEO for Google is automatically performing optimization for Google’s AI.
(There are a few caveats to this, which I can explain shortly.)
Get the newsletter search marketers rely on.
See terms.
Where different AI models get their data
But what about the other AI models? Where do they get their web data?
A survey of platforms suggests how one needs to optimize for AIs and where information may need to appear to feed them. It is important to note that there are two different things going on:
- Training data for large language models, which typically differs from fresh or current web search results, although there are obviously overlaps. Multiple major AIs were trained on data obtained from Common Crawl, a free source of web data that has been digested and stored in a format that is relatively easy for AIs to access, consume, and use.
- Sources of current or “live” web information, which are not necessarily the same as training data. Training sets could be a few years old, while contemporary web data may include information relevant to queries like “what are the current specials at Acme Restaurant?” or “have tickets for the Taylor Swift concert gone on sale?”
A recent revelation is that while some AIs were unable to obtain licenses for Google search results, they appear to be circumventing that by using SerpApi, a company that specializes in scraping Google SERPs.
Both OpenAI and Perplexity are reportedly making limited use of Google results through this indirect access.
| AI | Prime web data source | Other data sources |
| Google Gemini / AI Mode | Google Search | Digitized Books, YouTube Videos, Common Crawl |
| ChatGPT | Bing Search | Common Crawl, Google search via SerpApi (limited to current event data, such as news, sports, and markets) |
| Meta LLaMa | Google Search | Content from public Facebook & Instagram posts, Common Crawl |
| Microsoft Copilot | Bing Search | Common Crawl |
| Perplexity | PerplexityBot | Google search via SerpApi |
| Grok | Grok WebSearch | Posts on X.com |
| Claude | Brave Search | Common Crawl |
Why SEO still matters in the AI era
As you can see, many of the top AI chatbot and search systems are likely to reflect content that already ranks well in Google and Bing.
This supports the hypothesis that getting content surfaced in Google AI Mode, ChatGPT, Meta LLaMa, and Microsoft Copilot still depends on the established SEO methods long used to optimize for those search engines.
Google personnel have confirmed this, emphasizing the same high-level approaches they have advocated in recent years:
- Focus on unique, valuable content for people.
- Provide a great page experience.
- Ensure Googlebot can access your content.
- Manage visibility with preview controls (nosnippet and max-snippet).
- Make sure structured data matches the visible content.
- Go beyond text for multimodal success.
- Understand the full value of your visits.
- Evolve with your users.
For YMYL queries, your website also needs to convey trust, authority, and experience in the topic matter.
There has also been emphasis on structured data in AI optimization.
Google’s article “Top ways to ensure your content performs well in Google’s AI experiences on Search” reiterates that structured data should match visible content, a long-standing best practice.
What is notable is their added stress on validation, with the clear takeaway to use Google’s Rich Results Test and Schema Markup Validator to ensure pages have implemented markup properly.
Dig deeper: Answer engine optimization: 6 AI models you should optimize for
Caveats and complications
There are additional wrinkles depending on what you are trying to optimize.
As the melanoma treatment query example shows, you may need to optimize to appear for many search queries, not just one.
Other AI systems, like Gemini, are also likely to fan out to closely related queries when composing answers, so optimization may require targeting multiple queries rather than a single primary keyword phrase.
This creates a dilemma for publishers, since past Google updates have penalized thin pages built to target many keyword variations.
While I have not thoroughly researched this, there is some cause to think that broad content strategies covering many similar variations could be rewarded by AI while harming organic keyword rankings.
If considering such an approach, one should invest in specific, sophisticated, rich content for each variation, not content produced cheaply through automation or generative AI.
Where online reputation management is concerned, negative material in the top search results can be highlighted and even amplified in AI responses.
This is especially the case when multiple sources reiterate the same claims, which AI may present without important context.
For example:
- A news article states, “John Smith was accused of impropriety by Jane Jones, and he later sued her for defamation and prevailed.”
- AI might summarize it as, “Some sources have represented that John Smith may be guilty of impropriety.”
For reputation management, this means publishing multiple pieces of content across different domains to crowd out damaging material. It may even be rewarded by AIs that summarize top results.
Emerging gaps and unknowns
While optimization techniques and elements for Google and Bing are well-established, optimizing for some of the other search engines in the above chart is not so well-documented.
PerplexityBot
There are no known guidelines for optimizing for PerplexityBot.
One can assume that having solid technical SEO for a website will facilitate its content being crawled and absorbed by PerplexityBot.
Optimization beyond that is unknown.
Grok WebSearch
There are currently no known methods for optimizing for Grok WebSearch.
However, if you want a new website or webpage indexed for Grok, you should likely promote the URLs on X by posting them there as a signal for their bots to crawl and index the content.
Brave Search
This search engine does not have published optimization methods, but it states that much of its content discovery is through users’ web activities detected via the Brave browser.
Installing Brave would be a way to get the latest content added to the Brave Search engine.
One must opt in to sharing browsing data with Brave in order for one’s website visit activity to be submitted to them for indexation.
This feels pretty limiting and outdated, rather like submitting websites to search engines 20+ years ago.
Practical takeaways for search marketers
There may be more guidance on the horizon from generative AI providers, as companies and site owners continue to ask how they can get their content presented by AI – and why it may not be.
It has been said before, but it is worth reiterating that optimization strategies and content marketing should not be fueled purely by AI-generated content.
Each generative AI model has some vested interest in avoiding recursively created material because of the likelihood of error propagation and quality erosion.
When using AI in marketing and content creation, the long-term guidance is to focus deeply on quality and incorporate AI with a light hand, together with human oversight and QA.
Otherwise, producing large volumes of content cheaply with AI is likely to be a short-term tactic that is not sustainable, as many black-hat SEO strategies have already shown.
SEO is fuel for AI
Reassure yourself that “SEO is not dead.”
Each AI platform still needs to conduct searches among the trillions of webpages and other online content to deliver information.
The tried-and-true SEO techniques will remain necessary for the foreseeable future.
Even prior to the generative AI revolution, Google and other search engines were incorporating machine learning processes into their ranking algorithms.
Machine learning will likely continue to transform keyword search functions.
There is already a strong likelihood that Google and others are using models that create customized ranking methods and factor weightings by topic and query, as I have described in past work on Google’s quality scoring methods.
SEO is the fuel for the AI chatbots.
Each of them needs the content found among the trillions of webpages, with search engines working behind the scenes to help locate and organize it.
For webpages to be findable – and to rank well enough in the search engines feeding AI – SEO remains the essential connection between web content and the information ultimately delivered to users.




Recent Comments